Maxim Overview
Maxim AI provides comprehensive agent monitoring, evaluation, and observability for your CrewAI applications. With Maxim’s one-line integration, you can easily trace and analyse agent interactions, performance metrics, and more.Features
Prompt Management
Maxim’s Prompt Management capabilities enable you to create, organize, and optimize prompts for your CrewAI agents. Rather than hardcoding instructions, leverage Maxim’s SDK to dynamically retrieve and apply version-controlled prompts.- Prompt Playground
- Prompt Versions
- Prompt Comparisons
Create, refine, experiment and deploy your prompts via the playground. Organize of your prompts using folders and versions, experimenting with the real world cases by linking tools and context, and deploying based on custom logic.Easily experiment across models by configuring models and selecting the relevant model from the dropdown at the top of the prompt playground.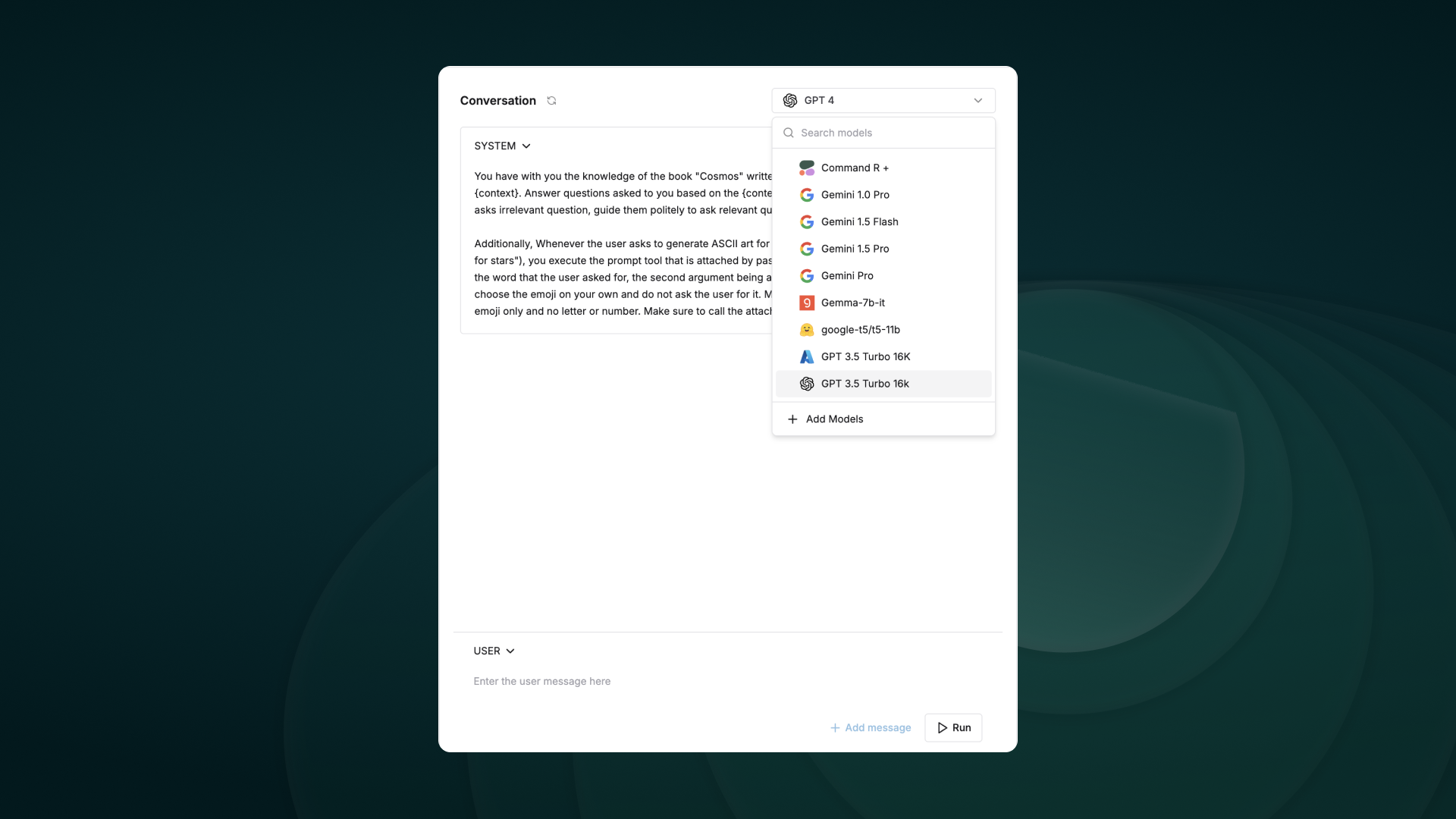
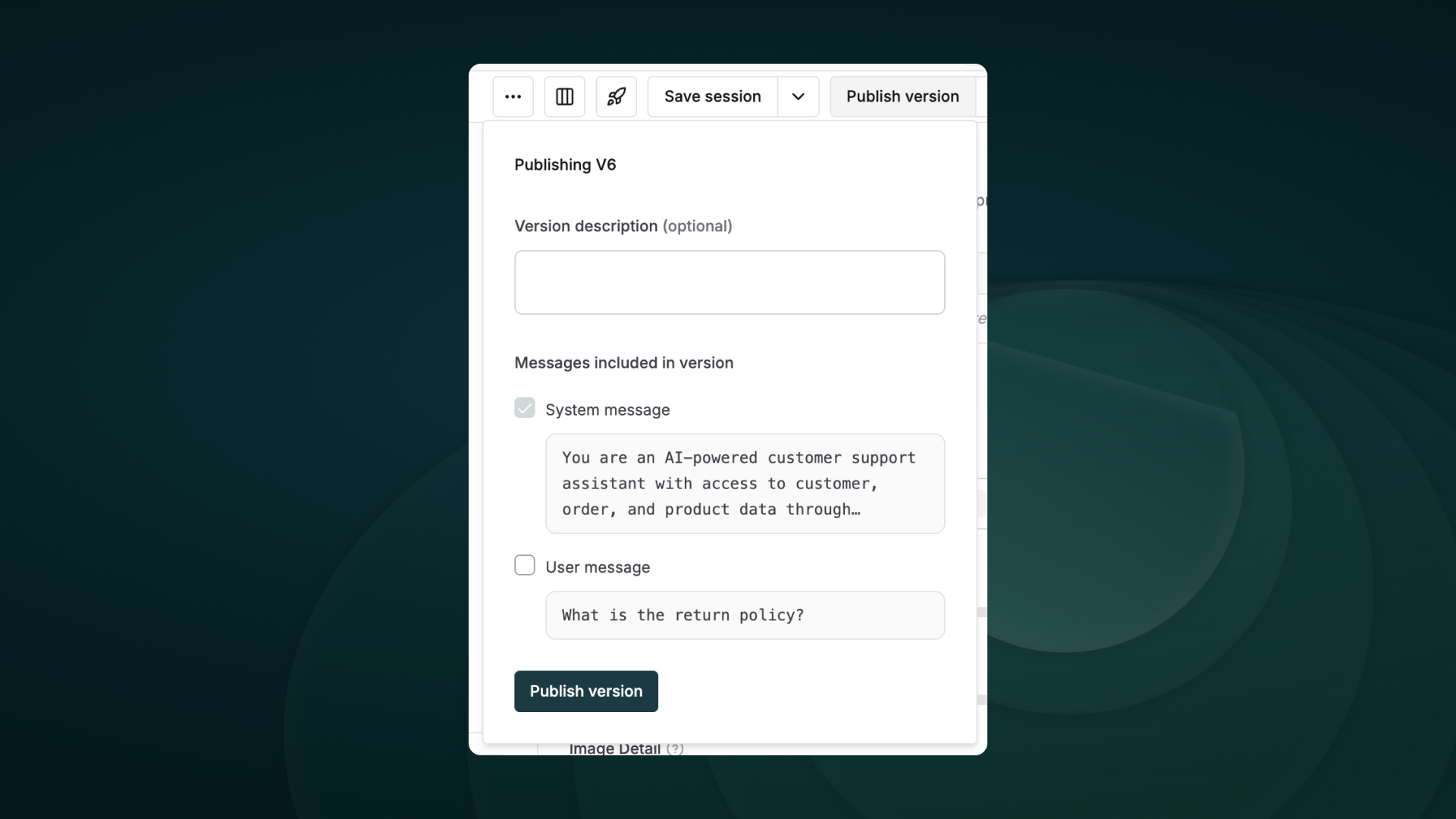
Observability & Evals
Maxim AI provides comprehensive observability & evaluation for your CrewAI agents, helping you understand exactly what’s happening during each execution.- Agent Tracing
- Analytics + Evals
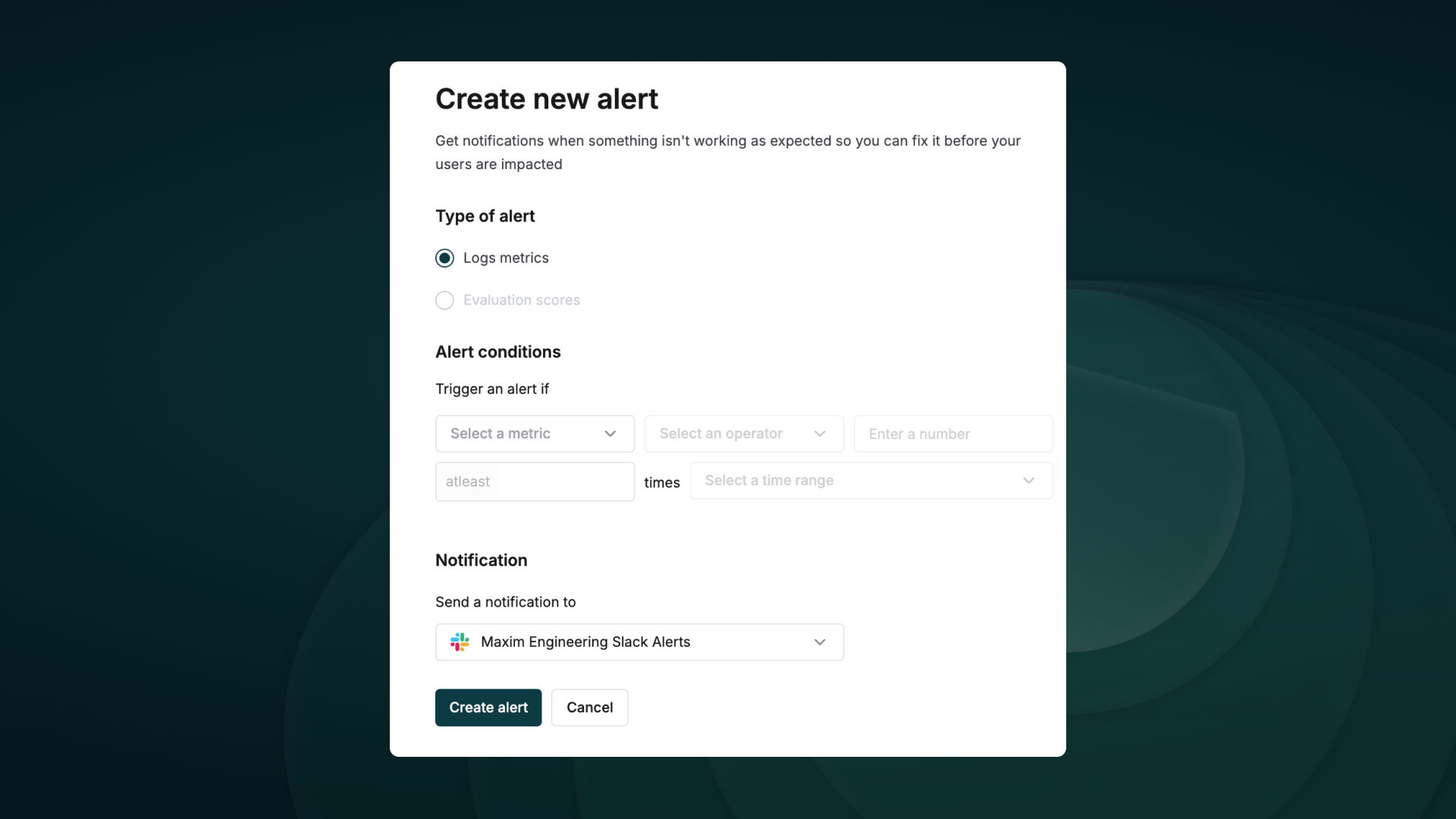
- Alerting
- Dashboards
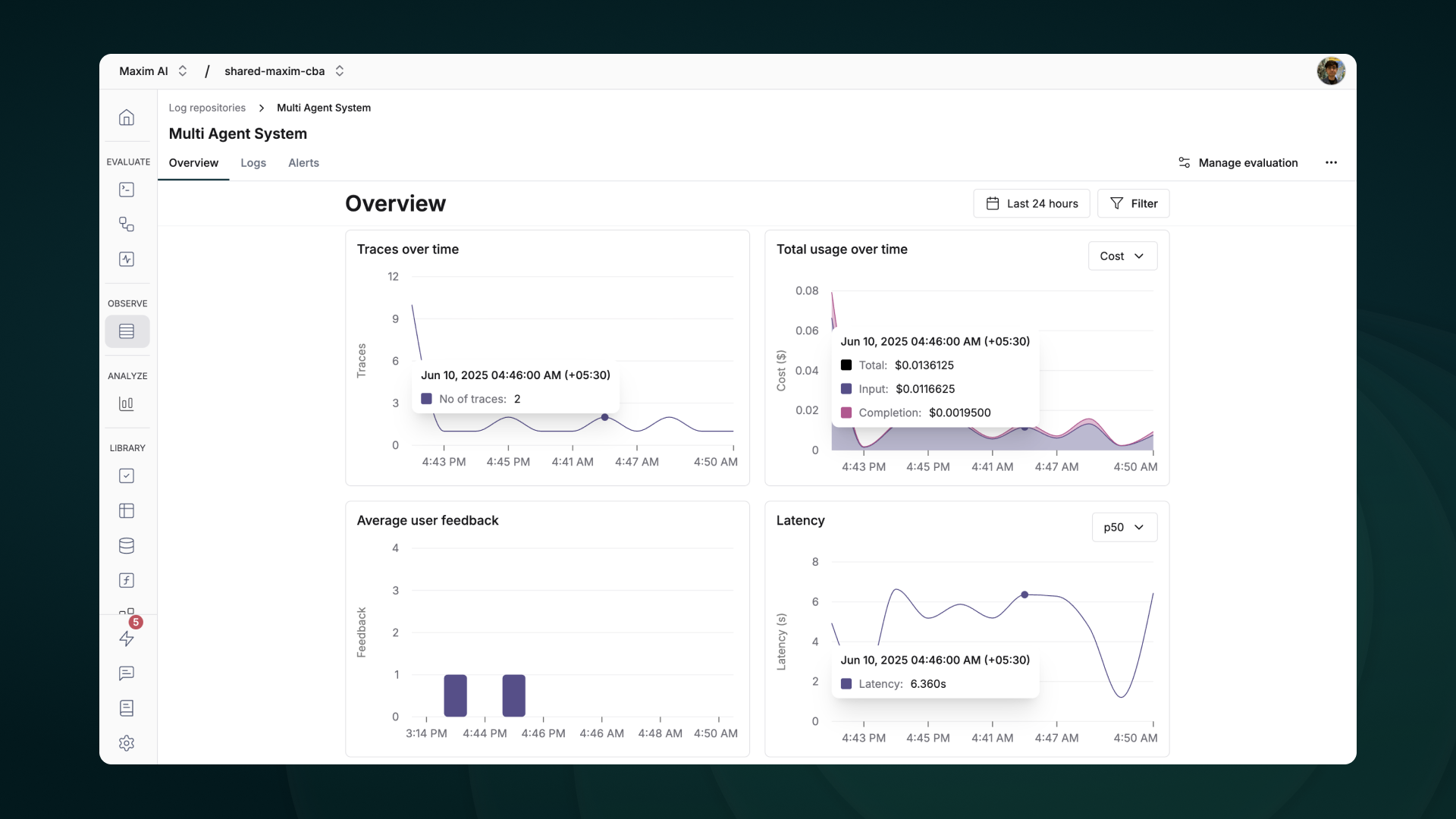
Track your agent’s complete lifecycle, including tool calls, agent trajectories, and decision flows effortlessly.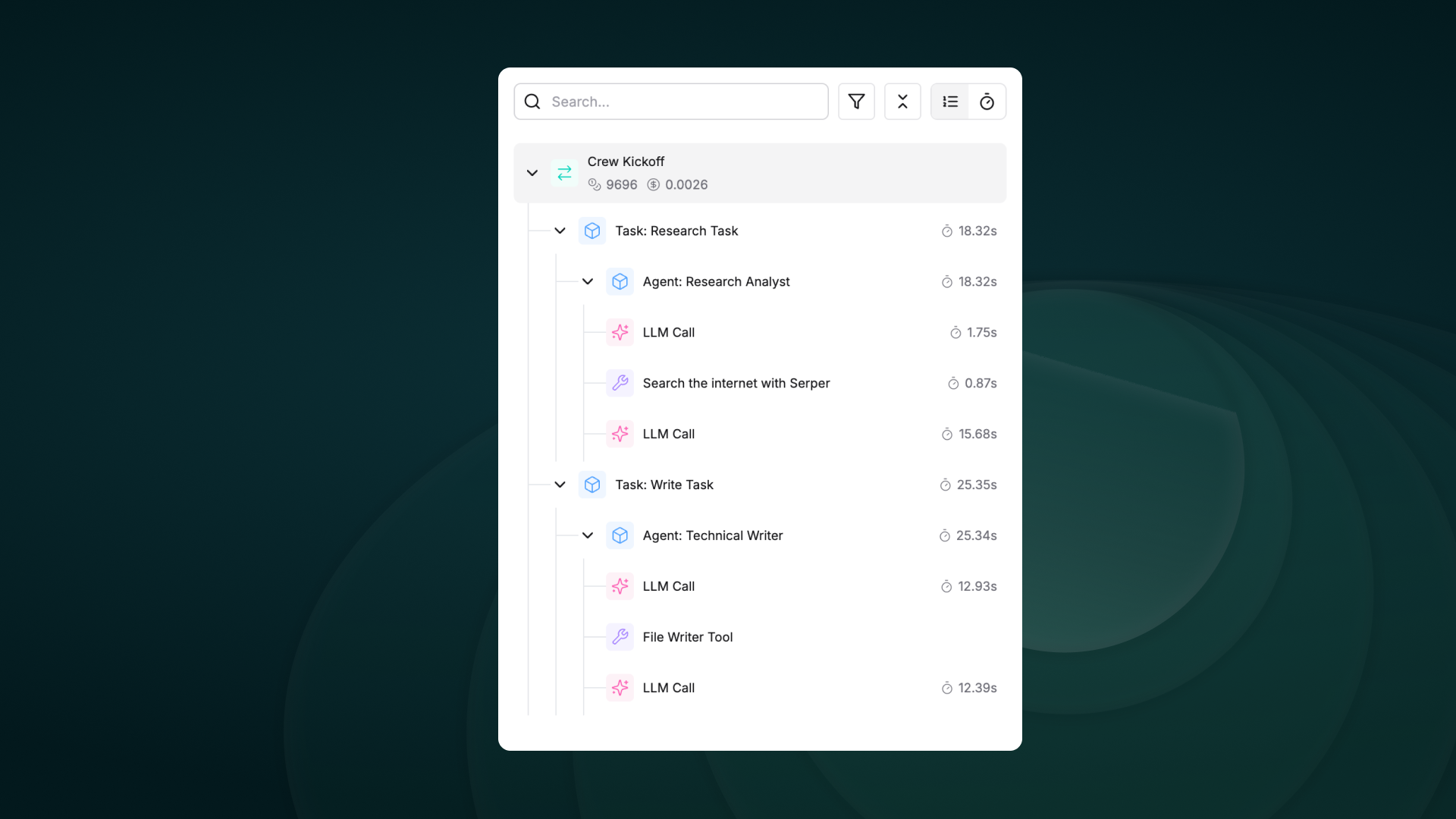
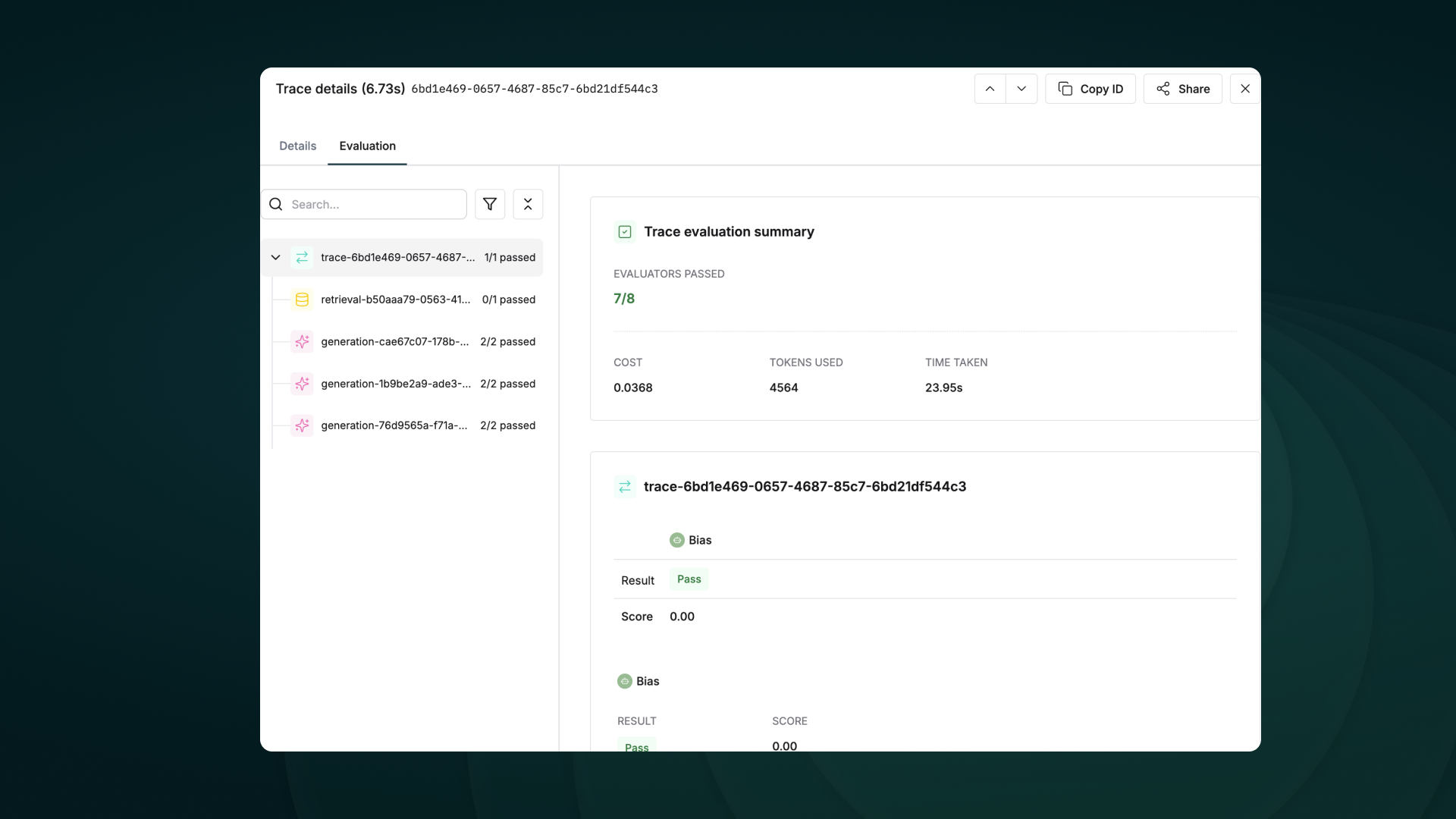
Getting Started
Prerequisites
- Python version >=3.10
- A Maxim account (sign up here)
- Generate Maxim API Key
- A CrewAI project
Installation
Install the Maxim SDK via pip:requirements.txt:
Basic Setup
1. Set up environment variables
2. Import the required packages
3. Initialise Maxim with your API key
4. Create and run your CrewAI application as usual
Viewing Your Traces
After running your CrewAI application:- Log in to your Maxim Dashboard
- Navigate to your repository
-
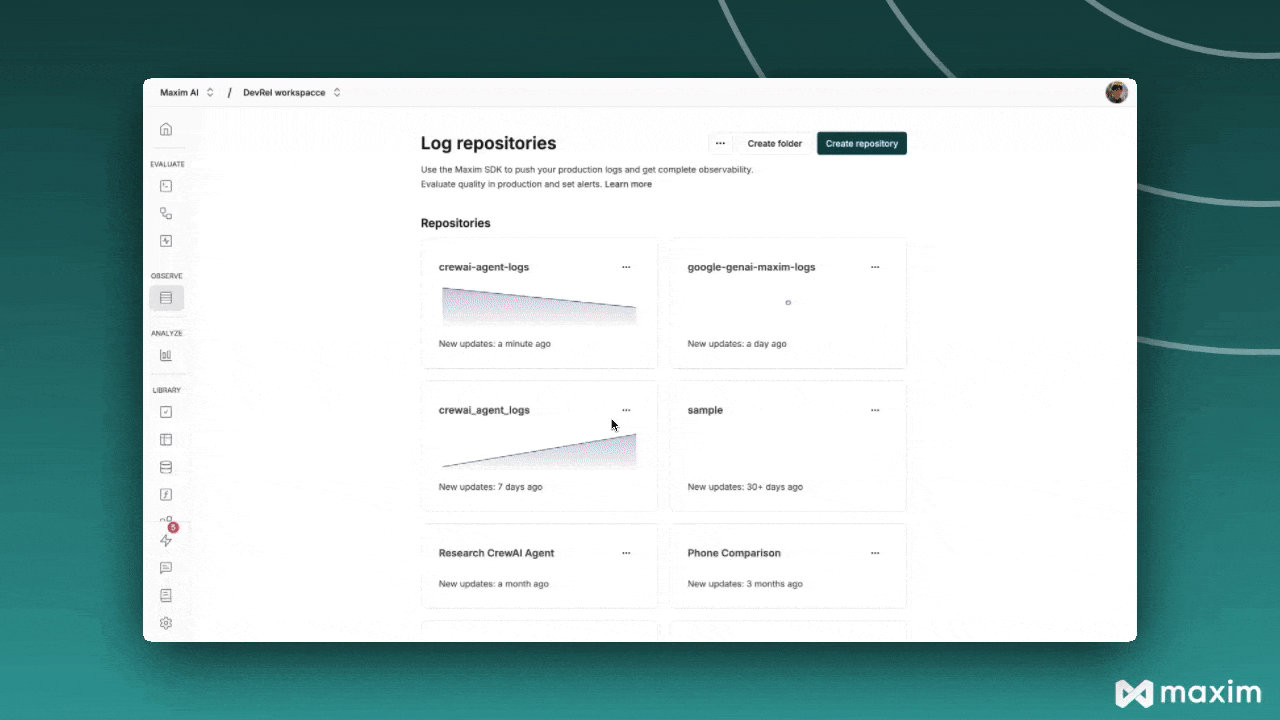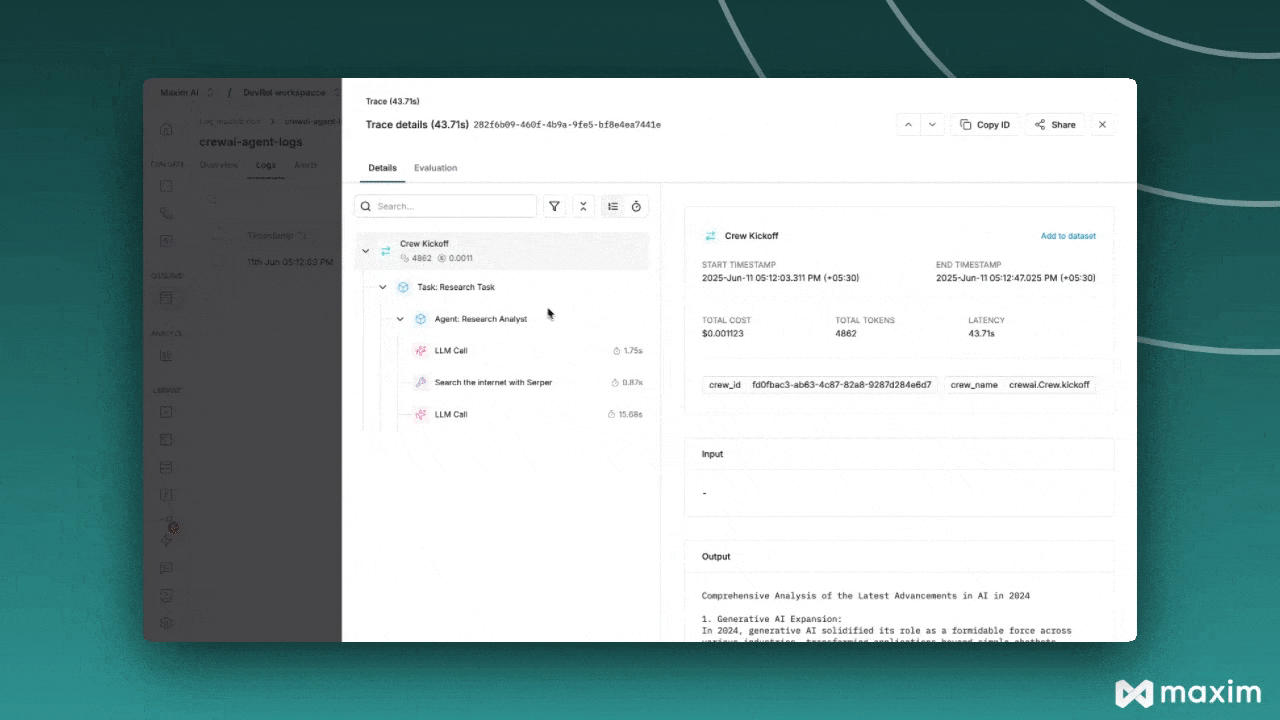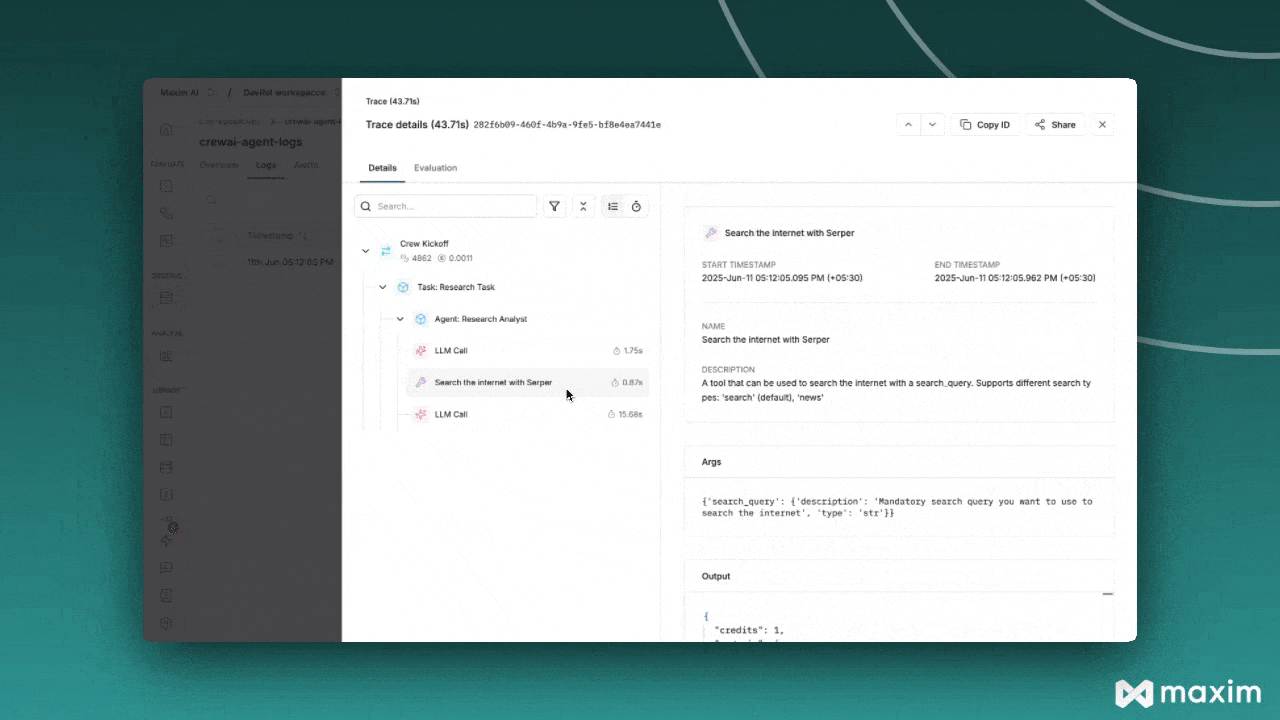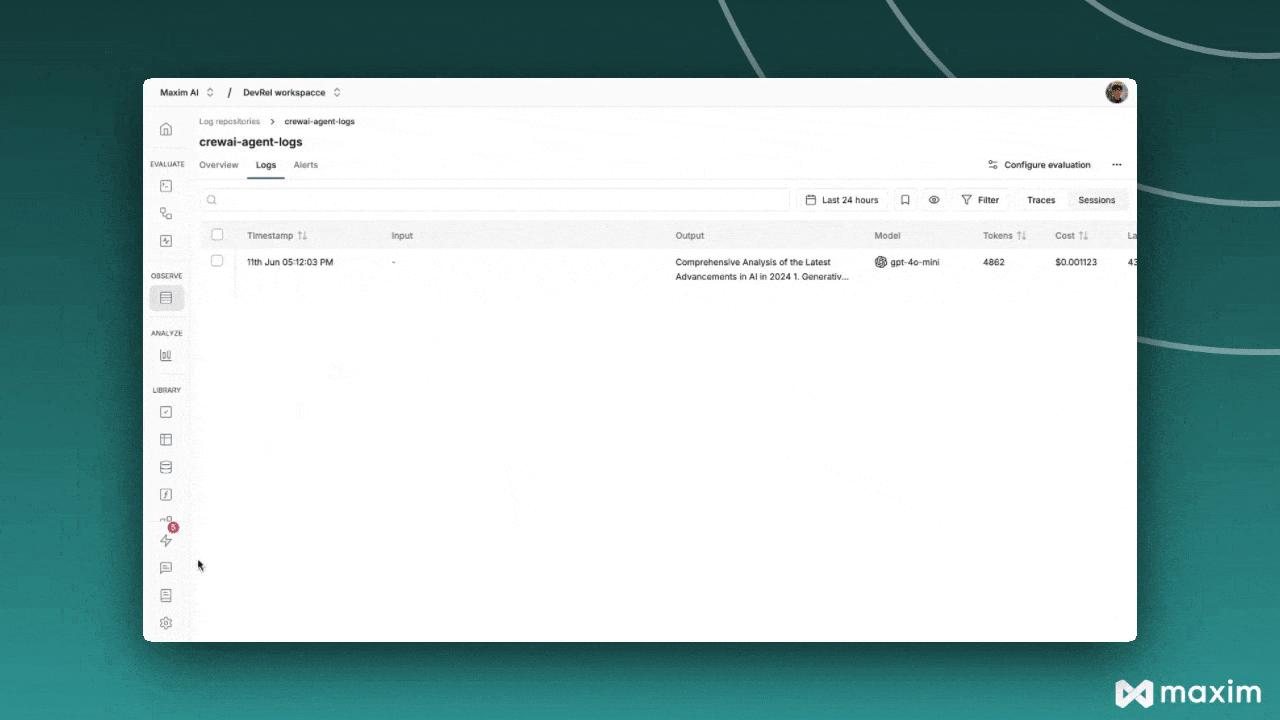
View detailed agent traces, including:
- Agent conversations
- Tool usage patterns
- Performance metrics
- Cost analytics
Troubleshooting
Common Issues
- No traces appearing: Ensure your API key and repository ID are correct
-
Ensure you’ve
called instrument_crewai()before running your crew. This initializes logging hooks correctly. -
Set
debug=Truein yourinstrument_crewai()call to surface any internal errors: -
Configure your agents with
verbose=Trueto capture detailed logs: -
Double-check that
instrument_crewai()is called before creating or executing agents. This might be obvious, but it’s a common oversight.
Resources
CrewAI Docs
Official CrewAI documentation
Maxim Docs
Official Maxim documentation
Maxim Github
Maxim Github