Rather than prescriptive model recommendations, we advocate for a thinking framework that helps you make informed decisions based on your specific use case, constraints, and requirements. The LLM landscape evolves rapidly, with new models emerging regularly and existing ones being updated frequently. What matters most is developing a systematic approach to evaluation that remains relevant regardless of which specific models are available.
This guide focuses on strategic thinking rather than specific model
recommendations, as the LLM landscape evolves rapidly.
Begin by deeply understanding what your tasks actually require. Consider the
cognitive complexity involved, the depth of reasoning needed, the format of
expected outputs, and the amount of context the model will need to process.
This foundational analysis will guide every subsequent decision.
2
Map Model Capabilities
Once you understand your requirements, map them to model strengths.
Different model families excel at different types of work; some are
optimized for reasoning and analysis, others for creativity and content
generation, and others for speed and efficiency.
3
Consider Constraints
Factor in your real-world operational constraints including budget
limitations, latency requirements, data privacy needs, and infrastructure
capabilities. The theoretically best model may not be the practically best
choice for your situation.
4
Test and Iterate
Start with reliable, well-understood models and optimize based on actual
performance in your specific use case. Real-world results often differ from
theoretical benchmarks, so empirical testing is crucial.
The most critical step in LLM selection is understanding what your task actually demands. Too often, teams select models based on general reputation or benchmark scores without carefully analyzing their specific requirements. This approach leads to either over-engineering simple tasks with expensive, complex models, or under-powering sophisticated work with models that lack the necessary capabilities.
Reasoning Complexity
Output Requirements
Context Needs
Simple Tasks represent the majority of everyday AI work and include basic instruction following, straightforward data processing, and simple formatting operations. These tasks typically have clear inputs and outputs with minimal ambiguity. The cognitive load is low, and the model primarily needs to follow explicit instructions rather than engage in complex reasoning.
Complex Tasks require multi-step reasoning, strategic thinking, and the ability to handle ambiguous or incomplete information. These might involve analyzing multiple data sources, developing comprehensive strategies, or solving problems that require breaking down into smaller components. The model needs to maintain context across multiple reasoning steps and often must make inferences that aren’t explicitly stated.
Creative Tasks demand a different type of cognitive capability focused on generating novel, engaging, and contextually appropriate content. This includes storytelling, marketing copy creation, and creative problem-solving. The model needs to understand nuance, tone, and audience while producing content that feels authentic and engaging rather than formulaic.
Structured Data tasks require precision and consistency in format adherence. When working with JSON, XML, or database formats, the model must reliably produce syntactically correct output that can be programmatically processed. These tasks often have strict validation requirements and little tolerance for format errors, making reliability more important than creativity.
Creative Content outputs demand a balance of technical competence and creative flair. The model needs to understand audience, tone, and brand voice while producing content that engages readers and achieves specific communication goals. Quality here is often subjective and requires models that can adapt their writing style to different contexts and purposes.
Technical Content sits between structured data and creative content, requiring both precision and clarity. Documentation, code generation, and technical analysis need to be accurate and comprehensive while remaining accessible to the intended audience. The model must understand complex technical concepts and communicate them effectively.
Short Context scenarios involve focused, immediate tasks where the model needs to process limited information quickly. These are often transactional interactions where speed and efficiency matter more than deep understanding. The model doesn’t need to maintain extensive conversation history or process large documents.
Long Context requirements emerge when working with substantial documents, extended conversations, or complex multi-part tasks. The model needs to maintain coherence across thousands of tokens while referencing earlier information accurately. This capability becomes crucial for document analysis, comprehensive research, and sophisticated dialogue systems.
Very Long Context scenarios push the boundaries of what’s currently possible, involving massive document processing, extensive research synthesis, or complex multi-session interactions. These use cases require models specifically designed for extended context handling and often involve trade-offs between context length and processing speed.
Understanding model capabilities requires looking beyond marketing claims and benchmark scores to understand the fundamental strengths and limitations of different model architectures and training approaches.
Reasoning Models
Reasoning models represent a specialized category designed specifically for complex, multi-step thinking tasks. These models excel when problems require careful analysis, strategic planning, or systematic problem decomposition. They typically employ techniques like chain-of-thought reasoning or tree-of-thought processing to work through complex problems step by step.The strength of reasoning models lies in their ability to maintain logical consistency across extended reasoning chains and to break down complex problems into manageable components. They’re particularly valuable for strategic planning, complex analysis, and situations where the quality of reasoning matters more than speed of response.However, reasoning models often come with trade-offs in terms of speed and cost. They may also be less suitable for creative tasks or simple operations where their sophisticated reasoning capabilities aren’t needed. Consider these models when your tasks involve genuine complexity that benefits from systematic, step-by-step analysis.
General Purpose Models
General purpose models offer the most balanced approach to LLM selection, providing solid performance across a wide range of tasks without extreme specialization in any particular area. These models are trained on diverse datasets and optimized for versatility rather than peak performance in specific domains.The primary advantage of general purpose models is their reliability and predictability across different types of work. They handle most standard business tasks competently, from research and analysis to content creation and data processing. This makes them excellent choices for teams that need consistent performance across varied workflows.While general purpose models may not achieve the peak performance of specialized alternatives in specific domains, they offer operational simplicity and reduced complexity in model management. They’re often the best starting point for new projects, allowing teams to understand their specific needs before potentially optimizing with more specialized models.
Fast & Efficient Models
Fast and efficient models prioritize speed, cost-effectiveness, and resource efficiency over sophisticated reasoning capabilities. These models are optimized for high-throughput scenarios where quick responses and low operational costs are more important than nuanced understanding or complex reasoning.These models excel in scenarios involving routine operations, simple data processing, function calling, and high-volume tasks where the cognitive requirements are relatively straightforward. They’re particularly valuable for applications that need to process many requests quickly or operate within tight budget constraints.The key consideration with efficient models is ensuring that their capabilities align with your task requirements. While they can handle many routine operations effectively, they may struggle with tasks requiring nuanced understanding, complex reasoning, or sophisticated content generation. They’re best used for well-defined, routine operations where speed and cost matter more than sophistication.
Creative Models
Creative models are specifically optimized for content generation, writing quality, and creative thinking tasks. These models typically excel at understanding nuance, tone, and style while producing engaging, contextually appropriate content that feels natural and authentic.The strength of creative models lies in their ability to adapt writing style to different audiences, maintain consistent voice and tone, and generate content that engages readers effectively. They often perform better on tasks involving storytelling, marketing copy, brand communications, and other content where creativity and engagement are primary goals.When selecting creative models, consider not just their ability to generate text, but their understanding of audience, context, and purpose. The best creative models can adapt their output to match specific brand voices, target different audience segments, and maintain consistency across extended content pieces.
Open Source Models
Open source models offer unique advantages in terms of cost control, customization potential, data privacy, and deployment flexibility. These models can be run locally or on private infrastructure, providing complete control over data handling and model behavior.The primary benefits of open source models include elimination of per-token costs, ability to fine-tune for specific use cases, complete data privacy, and independence from external API providers. They’re particularly valuable for organizations with strict data privacy requirements, budget constraints, or specific customization needs.However, open source models require more technical expertise to deploy and maintain effectively. Teams need to consider infrastructure costs, model management complexity, and the ongoing effort required to keep models updated and optimized. The total cost of ownership may be higher than cloud-based alternatives when factoring in technical overhead.
Use different models for different purposes within the same crew to optimize
both performance and cost.
The most sophisticated CrewAI implementations often employ multiple models strategically, assigning different models to different agents based on their specific roles and requirements. This approach allows teams to optimize for both performance and cost by using the most appropriate model for each type of work.Planning agents benefit from reasoning models that can handle complex strategic thinking and multi-step analysis. These agents often serve as the “brain” of the operation, developing strategies and coordinating other agents’ work. Content agents, on the other hand, perform best with creative models that excel at writing quality and audience engagement. Processing agents handling routine operations can use efficient models that prioritize speed and cost-effectiveness.Example: Research and Analysis Crew
from crewai import Agent, Task, Crew, LLM# High-capability reasoning model for strategic planningmanager_llm = LLM(model="gemini-2.5-flash-preview-05-20", temperature=0.1)# Creative model for content generationcontent_llm = LLM(model="claude-3-5-sonnet-20241022", temperature=0.7)# Efficient model for data processingprocessing_llm = LLM(model="gpt-4o-mini", temperature=0)research_manager = Agent( role="Research Strategy Manager", goal="Develop comprehensive research strategies and coordinate team efforts", backstory="Expert research strategist with deep analytical capabilities", llm=manager_llm, # High-capability model for complex reasoning verbose=True)content_writer = Agent( role="Research Content Writer", goal="Transform research findings into compelling, well-structured reports", backstory="Skilled writer who excels at making complex topics accessible", llm=content_llm, # Creative model for engaging content verbose=True)data_processor = Agent( role="Data Analysis Specialist", goal="Extract and organize key data points from research sources", backstory="Detail-oriented analyst focused on accuracy and efficiency", llm=processing_llm, # Fast, cost-effective model for routine tasks verbose=True)crew = Crew( agents=[research_manager, content_writer, data_processor], tasks=[...], # Your specific tasks manager_llm=manager_llm, # Manager uses the reasoning model verbose=True)
The key to successful multi-model implementation is understanding how different agents interact and ensuring that model capabilities align with agent responsibilities. This requires careful planning but can result in significant improvements in both output quality and operational efficiency.
The manager LLM plays a crucial role in hierarchical CrewAI processes, serving as the coordination point for multiple agents and tasks. This model needs to excel at delegation, task prioritization, and maintaining context across multiple concurrent operations.Effective manager LLMs require strong reasoning capabilities to make good delegation decisions, consistent performance to ensure predictable coordination, and excellent context management to track the state of multiple agents simultaneously. The model needs to understand the capabilities and limitations of different agents while optimizing task allocation for efficiency and quality.Cost considerations are particularly important for manager LLMs since they’re involved in every operation. The model needs to provide sufficient capability for effective coordination while remaining cost-effective for frequent use. This often means finding models that offer good reasoning capabilities without the premium pricing of the most sophisticated options.
Function calling LLMs handle tool usage across all agents, making them critical for crews that rely heavily on external tools and APIs. These models need to excel at understanding tool capabilities, extracting parameters accurately, and handling tool responses effectively.The most important characteristics for function calling LLMs are precision and reliability rather than creativity or sophisticated reasoning. The model needs to consistently extract the correct parameters from natural language requests and handle tool responses appropriately. Speed is also important since tool usage often involves multiple round trips that can impact overall performance.Many teams find that specialized function calling models or general purpose models with strong tool support work better than creative or reasoning-focused models for this role. The key is ensuring that the model can reliably bridge the gap between natural language instructions and structured tool calls.
Individual agents can override crew-level LLM settings when their specific needs differ significantly from the general crew requirements. This capability allows for fine-tuned optimization while maintaining operational simplicity for most agents.Consider agent-specific overrides when an agent’s role requires capabilities that differ substantially from other crew members. For example, a creative writing agent might benefit from a model optimized for content generation, while a data analysis agent might perform better with a reasoning-focused model.The challenge with agent-specific overrides is balancing optimization with operational complexity. Each additional model adds complexity to deployment, monitoring, and cost management. Teams should focus overrides on agents where the performance improvement justifies the additional complexity.
Effective task definition is often more important than model selection in determining the quality of CrewAI outputs. Well-defined tasks provide clear direction and context that enable even modest models to perform well, while poorly defined tasks can cause even sophisticated models to produce unsatisfactory results.
Effective Task Descriptions
The best task descriptions strike a balance between providing sufficient detail and maintaining clarity. They should define the specific objective clearly enough that there’s no ambiguity about what success looks like, while explaining the approach or methodology in enough detail that the agent understands how to proceed.Effective task descriptions include relevant context and constraints that help the agent understand the broader purpose and any limitations they need to work within. They break complex work into focused steps that can be executed systematically, rather than presenting overwhelming, multi-faceted objectives that are difficult to approach systematically.Common mistakes include being too vague about objectives, failing to provide necessary context, setting unclear success criteria, or combining multiple unrelated tasks into a single description. The goal is to provide enough information for the agent to succeed while maintaining focus on a single, clear objective.
Expected Output Guidelines
Expected output guidelines serve as a contract between the task definition and the agent, clearly specifying what the deliverable should look like and how it will be evaluated. These guidelines should describe both the format and structure needed, as well as the key elements that must be included for the output to be considered complete.The best output guidelines provide concrete examples of quality indicators and define completion criteria clearly enough that both the agent and human reviewers can assess whether the task has been completed successfully. This reduces ambiguity and helps ensure consistent results across multiple task executions.Avoid generic output descriptions that could apply to any task, missing format specifications that leave agents guessing about structure, unclear quality standards that make evaluation difficult, or failing to provide examples or templates that help agents understand expectations.
Sequential task dependencies are essential when tasks build upon previous outputs, information flows from one task to another, or quality depends on the completion of prerequisite work. This approach ensures that each task has access to the information and context it needs to succeed.Implementing sequential dependencies effectively requires using the context parameter to chain related tasks, building complexity gradually through task progression, and ensuring that each task produces outputs that serve as meaningful inputs for subsequent tasks. The goal is to maintain logical flow between dependent tasks while avoiding unnecessary bottlenecks.Sequential dependencies work best when there’s a clear logical progression from one task to another and when the output of one task genuinely improves the quality or feasibility of subsequent tasks. However, they can create bottlenecks if not managed carefully, so it’s important to identify which dependencies are truly necessary versus those that are merely convenient.
Parallel execution becomes valuable when tasks are independent of each other, time efficiency is important, or different expertise areas are involved that don’t require coordination. This approach can significantly reduce overall execution time while allowing specialized agents to work on their areas of strength simultaneously.Successful parallel execution requires identifying tasks that can truly run independently, grouping related but separate work streams effectively, and planning for result integration when parallel tasks need to be combined into a final deliverable. The key is ensuring that parallel tasks don’t create conflicts or redundancies that reduce overall quality.Consider parallel execution when you have multiple independent research streams, different types of analysis that don’t depend on each other, or content creation tasks that can be developed simultaneously. However, be mindful of resource allocation and ensure that parallel execution doesn’t overwhelm your available model capacity or budget.
Generic agent roles make it impossible to select the right LLM. Specific roles
enable targeted model optimization.
The specificity of your agent roles directly determines which LLM capabilities matter most for optimal performance. This creates a strategic opportunity to match precise model strengths with agent responsibilities.Generic vs. Specific Role Impact on LLM Choice:When defining roles, think about the specific domain knowledge, working style, and decision-making frameworks that would be most valuable for the tasks the agent will handle. The more specific and contextual the role definition, the better the model can embody that role effectively.
# ✅ Specific role - clear LLM requirementsspecific_agent = Agent( role="SaaS Revenue Operations Analyst", # Clear domain expertise needed goal="Analyze recurring revenue metrics and identify growth opportunities", backstory="Specialist in SaaS business models with deep understanding of ARR, churn, and expansion revenue", llm=LLM(model="gpt-4o") # Reasoning model justified for complex analysis)
Role-to-Model Mapping Strategy:
“Research Analyst” → Reasoning model (GPT-4o, Claude Sonnet) for complex analysis
“Content Editor” → Creative model (Claude, GPT-4o) for writing quality
“Data Processor” → Efficient model (GPT-4o-mini, Gemini Flash) for structured tasks
“API Coordinator” → Function-calling optimized model (GPT-4o, Claude) for tool usage
Strategic backstories multiply your chosen LLM’s effectiveness by providing
domain-specific context that generic prompting cannot achieve.
A well-crafted backstory transforms your LLM choice from generic capability to specialized expertise. This is especially crucial for cost optimization - a well-contextualized efficient model can outperform a premium model without proper context.Context-Driven Performance Example:
# Context amplifies model effectivenessdomain_expert = Agent( role="B2B SaaS Marketing Strategist", goal="Develop comprehensive go-to-market strategies for enterprise software", backstory=""" You have 10+ years of experience scaling B2B SaaS companies from Series A to IPO. You understand the nuances of enterprise sales cycles, the importance of product-market fit in different verticals, and how to balance growth metrics with unit economics. You've worked with companies like Salesforce, HubSpot, and emerging unicorns, giving you perspective on both established and disruptive go-to-market strategies. """, llm=LLM(model="claude-3-5-sonnet", temperature=0.3) # Balanced creativity with domain knowledge)# This context enables Claude to perform like a domain expert# Without it, even it would produce generic marketing advice
Backstory Elements That Enhance LLM Performance:
Domain Experience: “10+ years in enterprise SaaS sales”
Specific Expertise: “Specializes in technical due diligence for Series B+ rounds”
Working Style: “Prefers data-driven decisions with clear documentation”
Quality Standards: “Insists on citing sources and showing analytical work”
The most effective agent configurations create synergy between role specificity, backstory depth, and LLM selection. Each element reinforces the others to maximize model performance.Optimization Framework:
# Example: Technical Documentation Agenttech_writer = Agent( role="API Documentation Specialist", # Specific role for clear LLM requirements goal="Create comprehensive, developer-friendly API documentation", backstory=""" You're a technical writer with 8+ years documenting REST APIs, GraphQL endpoints, and SDK integration guides. You've worked with developer tools companies and understand what developers need: clear examples, comprehensive error handling, and practical use cases. You prioritize accuracy and usability over marketing fluff. """, llm=LLM( model="claude-3-5-sonnet", # Excellent for technical writing temperature=0.1 # Low temperature for accuracy ), tools=[code_analyzer_tool, api_scanner_tool], verbose=True)
Alignment Checklist:
✅ Role Specificity: Clear domain and responsibilities
✅ LLM Match: Model strengths align with role requirements
✅ Backstory Depth: Provides domain context the LLM can leverage
✅ Tool Integration: Tools support the agent’s specialized function
✅ Parameter Tuning: Temperature and settings optimize for role needs
The key is creating agents where every configuration choice reinforces your LLM selection strategy, maximizing performance while optimizing costs.
Rather than repeating the strategic framework, here’s a tactical checklist for implementing your LLM selection decisions in CrewAI:
Audit Your Current Setup
What to Review:
Are all agents using the same LLM by default?
Which agents handle the most complex reasoning tasks?
Which agents primarily do data processing or formatting?
Are any agents heavily tool-dependent?
Action: Document current agent roles and identify optimization opportunities.
Implement Crew-Level Strategy
Set Your Baseline:
# Start with a reliable default for the crewdefault_crew_llm = LLM(model="gpt-4o-mini") # Cost-effective baselinecrew = Crew( agents=[...], tasks=[...], memory=True)
Action: Establish your crew’s default LLM before optimizing individual agents.
Optimize High-Impact Agents
Identify and Upgrade Key Agents:
# Manager or coordination agentsmanager_agent = Agent( role="Project Manager", llm=LLM(model="gemini-2.5-flash-preview-05-20"), # Premium for coordination # ... rest of config)# Creative or customer-facing agentscontent_agent = Agent( role="Content Creator", llm=LLM(model="claude-3-5-sonnet"), # Best for writing # ... rest of config)
Action: Upgrade 20% of your agents that handle 80% of the complexity.
Reasoning models become essential when tasks require genuine multi-step logical thinking, strategic planning, or high-level decision making that benefits from systematic analysis. These models excel when problems need to be broken down into components and analyzed systematically rather than handled through pattern matching or simple instruction following.Consider reasoning models for business strategy development, complex data analysis that requires drawing insights from multiple sources, multi-step problem solving where each step depends on previous analysis, and strategic planning tasks that require considering multiple variables and their interactions.However, reasoning models often come with higher costs and slower response times, so they’re best reserved for tasks where their sophisticated capabilities provide genuine value rather than being used for simple operations that don’t require complex reasoning.
Creative models become valuable when content generation is the primary output and the quality, style, and engagement level of that content directly impact success. These models excel when writing quality and style matter significantly, creative ideation or brainstorming is needed, or brand voice and tone are important considerations.Use creative models for blog post writing and article creation, marketing copy that needs to engage and persuade, creative storytelling and narrative development, and brand communications where voice and tone are crucial. These models often understand nuance and context better than general purpose alternatives.Creative models may be less suitable for technical or analytical tasks where precision and factual accuracy are more important than engagement and style. They’re best used when the creative and communicative aspects of the output are primary success factors.
Efficient models are ideal for high-frequency, routine operations where speed and cost optimization are priorities. These models work best when tasks have clear, well-defined parameters and don’t require sophisticated reasoning or creative capabilities.Consider efficient models for data processing and transformation tasks, simple formatting and organization operations, function calling and tool usage where precision matters more than sophistication, and high-volume operations where cost per operation is a significant factor.The key with efficient models is ensuring that their capabilities align with task requirements. They can handle many routine operations effectively but may struggle with tasks requiring nuanced understanding, complex reasoning, or sophisticated content generation.
Open source models become attractive when budget constraints are significant, data privacy requirements exist, customization needs are important, or local deployment is required for operational or compliance reasons.Consider open source models for internal company tools where data privacy is paramount, privacy-sensitive applications that can’t use external APIs, cost-optimized deployments where per-token pricing is prohibitive, and situations requiring custom model modifications or fine-tuning.However, open source models require more technical expertise to deploy and maintain effectively. Consider the total cost of ownership including infrastructure, technical overhead, and ongoing maintenance when evaluating open source options.
The Problem: Using the same LLM for all agents in a crew, regardless of their specific roles and responsibilities. This is often the default approach but rarely optimal.Real Example: Using GPT-4o for both a strategic planning manager and a data extraction agent. The manager needs reasoning capabilities worth the premium cost, but the data extractor could perform just as well with GPT-4o-mini at a fraction of the price.CrewAI Solution: Leverage agent-specific LLM configuration to match model capabilities with agent roles:
The Problem: Not understanding how CrewAI’s LLM hierarchy works - crew LLM, manager LLM, and agent LLM settings can conflict or be poorly coordinated.Real Example: Setting a crew to use Claude, but having agents configured with GPT models, creating inconsistent behavior and unnecessary model switching overhead.CrewAI Solution: Plan your LLM hierarchy strategically:
crew = Crew( agents=[agent1, agent2], tasks=[task1, task2], manager_llm=LLM(model="gpt-4o"), # For crew coordination process=Process.hierarchical # When using manager_llm)# Agents inherit crew LLM unless specifically overriddenagent1 = Agent(llm=LLM(model="claude-3-5-sonnet")) # Override for specific needs
Function Calling Model Mismatch
The Problem: Choosing models based on general capabilities while ignoring function calling performance for tool-heavy CrewAI workflows.Real Example: Selecting a creative-focused model for an agent that primarily needs to call APIs, search tools, or process structured data. The agent struggles with tool parameter extraction and reliable function calls.CrewAI Solution: Prioritize function calling capabilities for tool-heavy agents:
# For agents that use many toolstool_agent = Agent( role="API Integration Specialist", tools=[search_tool, api_tool, data_tool], llm=LLM(model="gpt-4o"), # Excellent function calling # OR llm=LLM(model="claude-3-5-sonnet") # Also strong with tools)
Premature Optimization Without Testing
The Problem: Making complex model selection decisions based on theoretical performance without validating with actual CrewAI workflows and tasks.Real Example: Implementing elaborate model switching logic based on task types without testing if the performance gains justify the operational complexity.CrewAI Solution: Start simple, then optimize based on real performance data:
# Start with thiscrew = Crew(agents=[...], tasks=[...], llm=LLM(model="gpt-4o-mini"))# Test performance, then optimize specific agents as needed# Use Enterprise platform testing to validate improvements
Overlooking Context and Memory Limitations
The Problem: Not considering how model context windows interact with CrewAI’s memory and context sharing between agents.Real Example: Using a short-context model for agents that need to maintain conversation history across multiple task iterations, or in crews with extensive agent-to-agent communication.CrewAI Solution: Match context capabilities to crew communication patterns.
Begin with reliable, general-purpose models that are well-understood and
widely supported. This provides a stable foundation for understanding your
specific requirements and performance expectations before optimizing for
specialized needs.
Measure What Matters
Develop metrics that align with your specific use case and business
requirements rather than relying solely on general benchmarks. Focus on
measuring outcomes that directly impact your success rather than theoretical
performance indicators.
Iterate Based on Results
Make model changes based on observed performance in your specific context
rather than theoretical considerations or general recommendations.
Real-world performance often differs significantly from benchmark results or
general reputation.
Consider Total Cost
Evaluate the complete cost of ownership including model costs, development
time, maintenance overhead, and operational complexity. The cheapest model
per token may not be the most cost-effective choice when considering all
factors.
Focus on understanding your requirements first, then select models that best
match those needs. The best LLM choice is the one that consistently delivers
the results you need within your operational constraints.
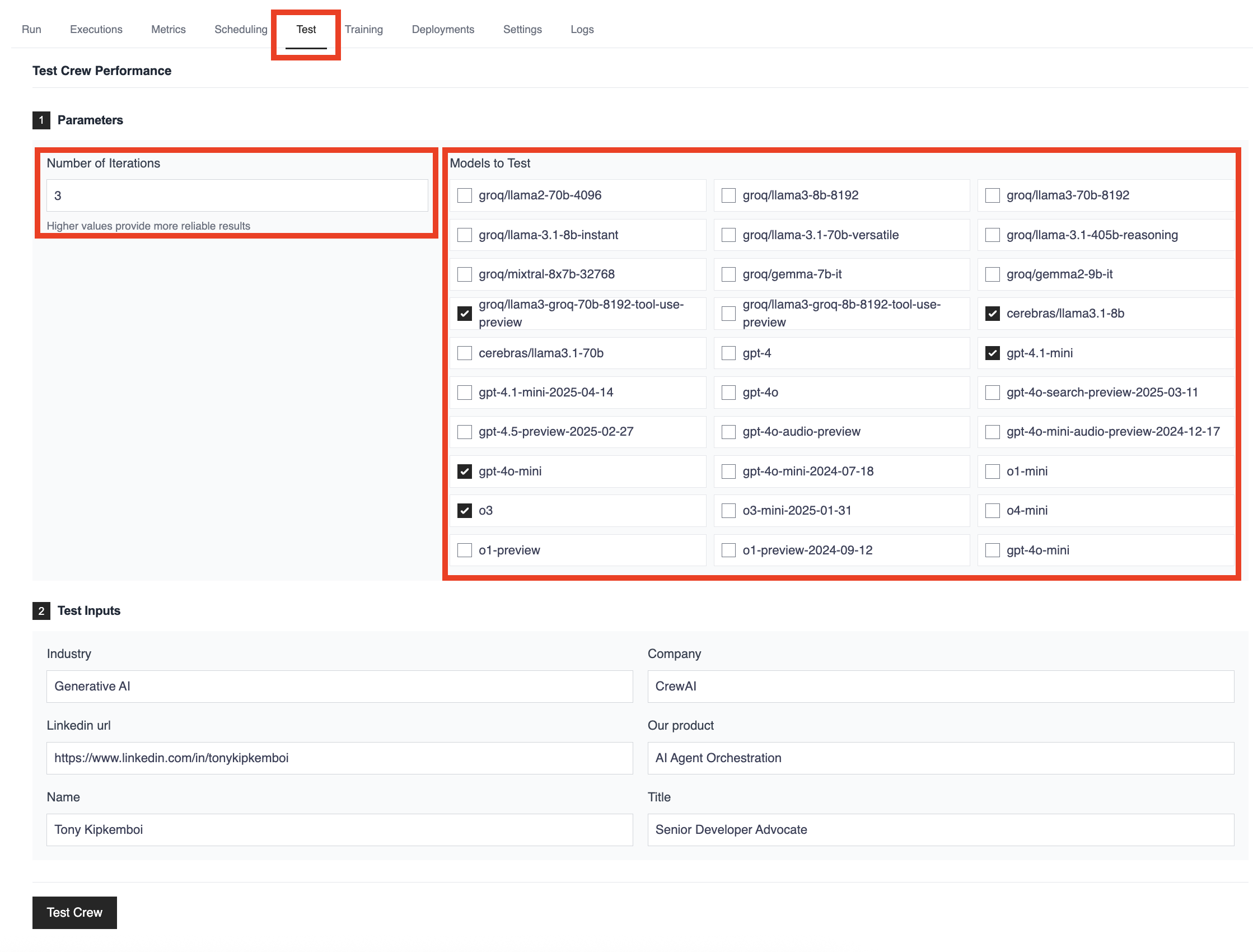
For teams serious about optimizing their LLM selection, the CrewAI AMP platform provides sophisticated testing capabilities that go far beyond basic CLI testing. The platform enables comprehensive model evaluation that helps you make data-driven decisions about your LLM strategy.
Advanced Testing Features:
Multi-Model Comparison: Test multiple LLMs simultaneously across the same tasks and inputs. Compare performance between GPT-4o, Claude, Llama, Groq, Cerebras, and other leading models in parallel to identify the best fit for your specific use case.
Statistical Rigor: Configure multiple iterations with consistent inputs to measure reliability and performance variance. This helps identify models that not only perform well but do so consistently across runs.
Real-World Validation: Use your actual crew inputs and scenarios rather than synthetic benchmarks. The platform allows you to test with your specific industry context, company information, and real use cases for more accurate evaluation.
Comprehensive Analytics: Access detailed performance metrics, execution times, and cost analysis across all tested models. This enables data-driven decision making rather than relying on general model reputation or theoretical capabilities.
Team Collaboration: Share testing results and model performance data across your team, enabling collaborative decision-making and consistent model selection strategies across projects.
The Enterprise platform transforms model selection from guesswork into a
data-driven process, enabling you to validate the principles in this guide
with your actual use cases and requirements.
Choose models based on what the task actually requires, not theoretical capabilities or general reputation.
Capability Matching
Align model strengths with agent roles and responsibilities for optimal
performance.
Strategic Consistency
Maintain coherent model selection strategy across related components and
workflows.
Practical Testing
Validate choices through real-world usage rather than benchmarks alone.
Iterative Improvement
Start simple and optimize based on actual performance and needs.
Operational Balance
Balance performance requirements with cost and complexity constraints.
Remember: The best LLM choice is the one that consistently delivers the
results you need within your operational constraints. Focus on understanding
your requirements first, then select models that best match those needs.
Snapshot in Time: The following model rankings represent current
leaderboard standings as of June 2025, compiled from LMSys
Arena, Artificial
Analysis, and other leading benchmarks. LLM
performance, availability, and pricing change rapidly. Always conduct your own
evaluations with your specific use cases and data.
The tables below show a representative sample of current top-performing models across different categories, with guidance on their suitability for CrewAI agents:
These tables/metrics showcase selected leading models in each category and are
not exhaustive. Many excellent models exist beyond those listed here. The goal
is to illustrate the types of capabilities to look for rather than provide a
complete catalog.
Reasoning & Planning
Coding & Technical
Speed & Efficiency
Balanced Performance
Best for Manager LLMs and Complex Analysis
Model
Intelligence Score
Cost ($/M tokens)
Speed
Best Use in CrewAI
o3
70
$17.50
Fast
Manager LLM for complex multi-agent coordination
Gemini 2.5 Pro
69
$3.44
Fast
Strategic planning agents, research coordination
DeepSeek R1
68
$0.96
Moderate
Cost-effective reasoning for budget-conscious crews
Claude 4 Sonnet
53
$6.00
Fast
Analysis agents requiring nuanced understanding
Qwen3 235B (Reasoning)
62
$2.63
Moderate
Open-source alternative for reasoning tasks
These models excel at multi-step reasoning and are ideal for agents that need to develop strategies, coordinate other agents, or analyze complex information.
Best for Development and Tool-Heavy Workflows
Model
Coding Performance
Tool Use Score
Cost ($/M tokens)
Best Use in CrewAI
Claude 4 Sonnet
Excellent
72.7%
$6.00
Primary coding agent, technical documentation
Claude 4 Opus
Excellent
72.5%
$30.00
Complex software architecture, code review
DeepSeek V3
Very Good
High
$0.48
Cost-effective coding for routine development
Qwen2.5 Coder 32B
Very Good
Medium
$0.15
Budget-friendly coding agent
Llama 3.1 405B
Good
81.1%
$3.50
Function calling LLM for tool-heavy workflows
These models are optimized for code generation, debugging, and technical problem-solving, making them ideal for development-focused crews.
Best for High-Throughput and Real-Time Applications
Model
Speed (tokens/s)
Latency (TTFT)
Cost ($/M tokens)
Best Use in CrewAI
Llama 4 Scout
2,600
0.33s
$0.27
High-volume processing agents
Gemini 2.5 Flash
376
0.30s
$0.26
Real-time response agents
DeepSeek R1 Distill
383
Variable
$0.04
Cost-optimized high-speed processing
Llama 3.3 70B
2,500
0.52s
$0.60
Balanced speed and capability
Nova Micro
High
0.30s
$0.04
Simple, fast task execution
These models prioritize speed and efficiency, perfect for agents handling routine operations or requiring quick responses. Pro tip: Pairing these models with fast inference providers like Groq can achieve even better performance, especially for open-source models like Llama.
Best All-Around Models for General Crews
Model
Overall Score
Versatility
Cost ($/M tokens)
Best Use in CrewAI
GPT-4.1
53
Excellent
$3.50
General-purpose crew LLM
Claude 3.7 Sonnet
48
Very Good
$6.00
Balanced reasoning and creativity
Gemini 2.0 Flash
48
Good
$0.17
Cost-effective general use
Llama 4 Maverick
51
Good
$0.37
Open-source general purpose
Qwen3 32B
44
Good
$1.23
Budget-friendly versatility
These models offer good performance across multiple dimensions, suitable for crews with diverse task requirements.
When performance is the priority: Use top-tier models like o3, Gemini 2.5 Pro, or Claude 4 Sonnet for manager LLMs and critical agents. These models excel at complex reasoning and coordination but come with higher costs.Strategy: Implement a multi-model approach where premium models handle strategic thinking while efficient models handle routine operations.
Cost-Conscious Crews
When budget is a primary constraint: Focus on models like DeepSeek R1, Llama 4 Scout, or Gemini 2.0 Flash. These provide strong performance at significantly lower costs.Strategy: Use cost-effective models for most agents, reserving premium models only for the most critical decision-making roles.
Specialized Workflows
For specific domain expertise: Choose models optimized for your primary use case. Claude 4 series for coding, Gemini 2.5 Pro for research, Llama 405B for function calling.Strategy: Select models based on your crew’s primary function, ensuring the core capability aligns with model strengths.
Enterprise & Privacy
For data-sensitive operations: Consider open-source models like Llama 4 series, DeepSeek V3, or Qwen3 that can be deployed locally while maintaining competitive performance.Strategy: Deploy open-source models on private infrastructure, accepting potential performance trade-offs for data control.
Performance Trends: The current landscape shows strong competition between reasoning-focused models (o3, Gemini 2.5 Pro) and balanced models (Claude 4, GPT-4.1). Specialized models like DeepSeek R1 offer excellent cost-performance ratios.
Speed vs. Intelligence Trade-offs: Models like Llama 4 Scout prioritize speed (2,600 tokens/s) while maintaining reasonable intelligence, whereas models like o3 maximize reasoning capability at the cost of speed and price.
Open Source Viability: The gap between open-source and proprietary models continues to narrow, with models like Llama 4 Maverick and DeepSeek V3 offering competitive performance at attractive price points. Fast inference providers particularly shine with open-source models, often delivering better speed-to-cost ratios than proprietary alternatives.
Testing is Essential: Leaderboard rankings provide general guidance, but
your specific use case, prompting style, and evaluation criteria may produce
different results. Always test candidate models with your actual tasks and
data before making final decisions.
Begin with well-established models like GPT-4.1, Claude 3.7 Sonnet, or Gemini 2.0 Flash that offer good performance across multiple dimensions and have extensive real-world validation.
2
Identify Specialized Needs
Determine if your crew has specific requirements (coding, reasoning, speed)
that would benefit from specialized models like Claude 4 Sonnet for
development or o3 for complex analysis. For speed-critical applications,
consider fast inference providers like Groq alongside model selection.
3
Implement Multi-Model Strategy
Use different models for different agents based on their roles.
High-capability models for managers and complex tasks, efficient models for
routine operations.
4
Monitor and Optimize
Track performance metrics relevant to your use case and be prepared to adjust model selections as new models are released or pricing changes.