What is CrewAI?
CrewAI is a lean, lightning-fast Python framework built entirely from scratch—completely independent of LangChain or other agent frameworks. CrewAI empowers developers with both high-level simplicity and precise low-level control, ideal for creating autonomous AI agents tailored to any scenario:- CrewAI Crews: Optimize for autonomy and collaborative intelligence, enabling you to create AI teams where each agent has specific roles, tools, and goals.
- CrewAI Flows: Enable granular, event-driven control, single LLM calls for precise task orchestration and supports Crews natively.
How Crews Work
Just like a company has departments (Sales, Engineering, Marketing) working together under leadership to achieve business goals, CrewAI helps you create an organization of AI agents with specialized roles collaborating to accomplish complex tasks.
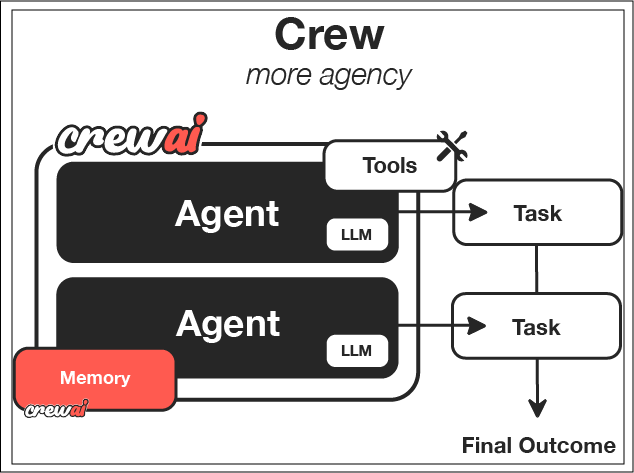
CrewAI Framework Overview
| Component | Description | Key Features |
|---|---|---|
| Crew | The top-level organization | • Manages AI agent teams • Oversees workflows • Ensures collaboration • Delivers outcomes |
| AI Agents | Specialized team members | • Have specific roles (researcher, writer) • Use designated tools • Can delegate tasks • Make autonomous decisions |
| Process | Workflow management system | • Defines collaboration patterns • Controls task assignments • Manages interactions • Ensures efficient execution |
| Tasks | Individual assignments | • Have clear objectives • Use specific tools • Feed into larger process • Produce actionable results |
How It All Works Together
- The Crew organizes the overall operation
- AI Agents work on their specialized tasks
- The Process ensures smooth collaboration
- Tasks get completed to achieve the goal
Key Features
Role-Based Agents
Create specialized agents with defined roles, expertise, and goals - from researchers to analysts to writers
Flexible Tools
Equip agents with custom tools and APIs to interact with external services and data sources
Intelligent Collaboration
Agents work together, sharing insights and coordinating tasks to achieve complex objectives
Task Management
Define sequential or parallel workflows, with agents automatically handling task dependencies
How Flows Work
While Crews excel at autonomous collaboration, Flows provide structured automations, offering granular control over workflow execution. Flows ensure tasks are executed reliably, securely, and efficiently, handling conditional logic, loops, and dynamic state management with precision. Flows integrate seamlessly with Crews, enabling you to balance high autonomy with exacting control.
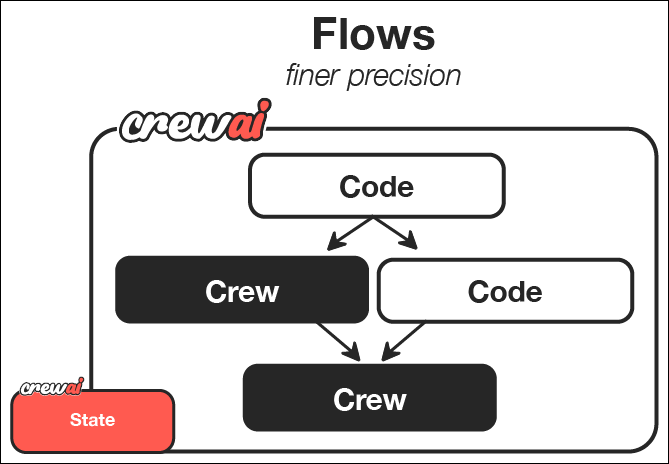
CrewAI Framework Overview
| Component | Description | Key Features |
|---|---|---|
| Flow | Structured workflow orchestration | • Manages execution paths • Handles state transitions • Controls task sequencing • Ensures reliable execution |
| Events | Triggers for workflow actions | • Initiate specific processes • Enable dynamic responses • Support conditional branching • Allow for real-time adaptation |
| States | Workflow execution contexts | • Maintain execution data • Enable persistence • Support resumability • Ensure execution integrity |
| Crew Support | Enhances workflow automation | • Injects pockets of agency when needed • Complements structured workflows • Balances automation with intelligence • Enables adaptive decision-making |
Key Capabilities
Event-Driven Orchestration
Define precise execution paths responding dynamically to events
Fine-Grained Control
Manage workflow states and conditional execution securely and efficiently
Native Crew Integration
Effortlessly combine with Crews for enhanced autonomy and intelligence
Deterministic Execution
Ensure predictable outcomes with explicit control flow and error handling
When to Use Crews vs. Flows
| Use Case | Recommended Approach | Why? |
|---|---|---|
| Open-ended research | Crews | When tasks require creative thinking, exploration, and adaptation |
| Content generation | Crews | For collaborative creation of articles, reports, or marketing materials |
| Decision workflows | Flows | When you need predictable, auditable decision paths with precise control |
| API orchestration | Flows | For reliable integration with multiple external services in a specific sequence |
| Hybrid applications | Combined approach | Use Flows to orchestrate overall process with Crews handling complex subtasks |
Decision Framework
- Choose Crews when: You need autonomous problem-solving, creative collaboration, or exploratory tasks
- Choose Flows when: You require deterministic outcomes, auditability, or precise control over execution
- Combine both when: Your application needs both structured processes and pockets of autonomous intelligence
Why Choose CrewAI?
- 🧠 Autonomous Operation: Agents make intelligent decisions based on their roles and available tools
- 📝 Natural Interaction: Agents communicate and collaborate like human team members
- 🛠️ Extensible Design: Easy to add new tools, roles, and capabilities
- 🚀 Production Ready: Built for reliability and scalability in real-world applications
- 🔒 Security-Focused: Designed with enterprise security requirements in mind
- 💰 Cost-Efficient: Optimized to minimize token usage and API calls