نظرة عامة
في إطار عمل CrewAI، المهمة (Task) هي تكليف محدد يُنجزه وكيل (Agent).
توفر المهام جميع التفاصيل اللازمة للتنفيذ، مثل الوصف والوكيل المسؤول والأدوات المطلوبة والمزيد، مما يسهّل مجموعة واسعة من تعقيدات الإجراءات.
يمكن أن تكون المهام في CrewAI تعاونية، تتطلب عمل وكلاء متعددين معًا. تتم إدارة ذلك من خلال خصائص المهمة ويتم تنسيقه بواسطة عملية Crew، مما يعزز العمل الجماعي والكفاءة.
يتضمن CrewAI AMP منشئ مهام مرئي في Crew Studio يبسّط إنشاء المهام المعقدة وربطها. صمم تدفقات مهامك بصريًا واختبرها في الوقت الفعلي دون كتابة كود.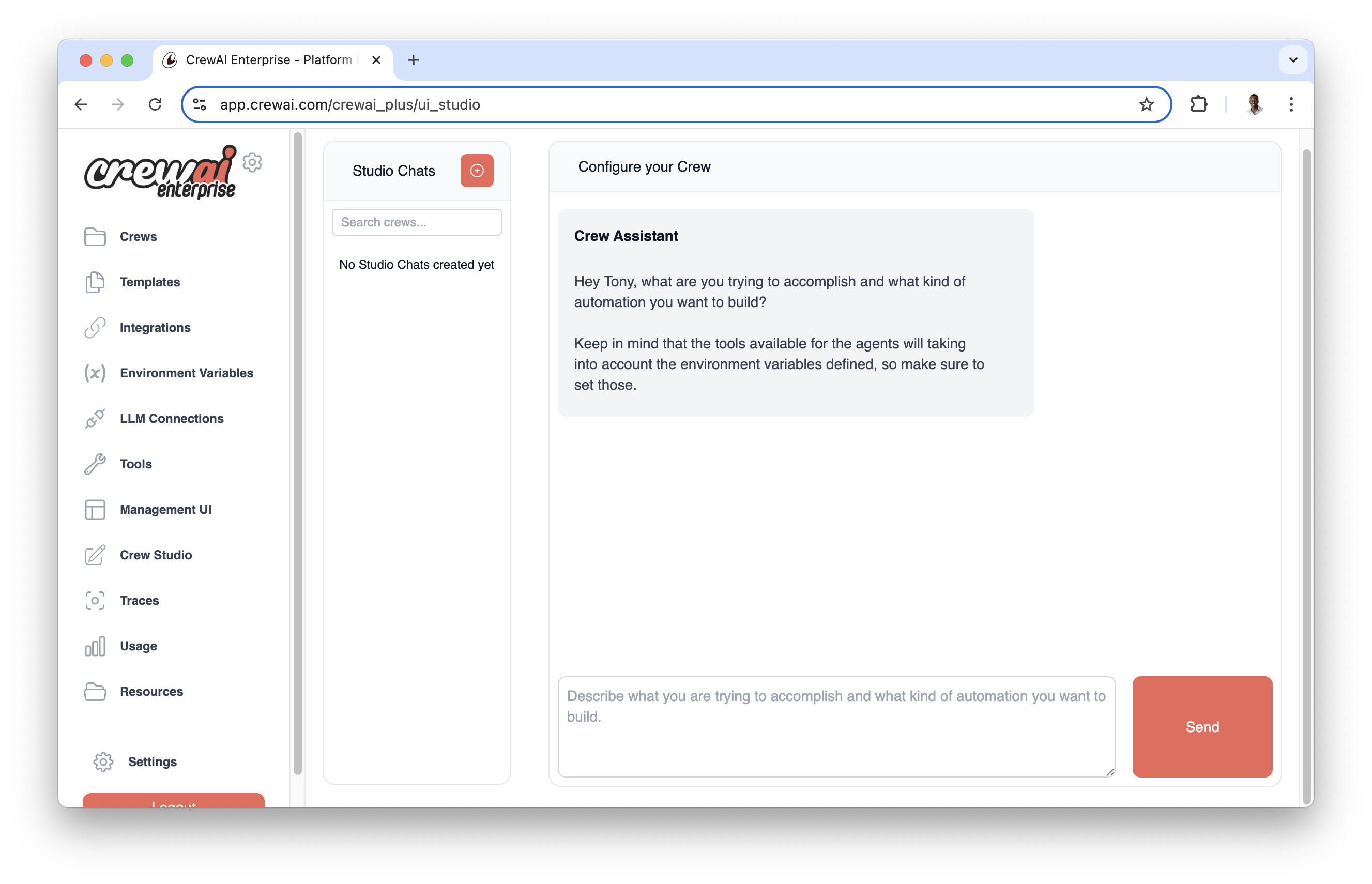
- إنشاء المهام بالسحب والإفلات
- تبعيات المهام المرئية والتدفق
- الاختبار والتحقق في الوقت الفعلي
- المشاركة والتعاون بسهولة
تدفق تنفيذ المهام
يمكن تنفيذ المهام بطريقتين:- تسلسلي: تُنفَّذ المهام بالترتيب الذي تم تعريفها به
- هرمي: تُعيَّن المهام للوكلاء بناءً على أدوارهم وخبراتهم
Code
خصائص المهمة
خاصية المهمة
max_retries مهملة وستتم إزالتها في v1.0.0.
استخدم guardrail_max_retries بدلاً منها للتحكم في محاولات الإعادة عند فشل الحارس.إنشاء المهام
هناك طريقتان شائعتان لإنشاء المهام في CrewAI: باستخدام تهيئة JSONC (الموصى بها للـ crews الجديدة) أو تعريفها مباشرة في الكود.تهيئة JSONC (موصى بها)
المشاريع الجديدة التي تُنشأ عبرcrewai create crew <name> تعرّف المهام في crew.jsonc.
crew.jsonc
description و expected_output. يجب أن يطابق agent اسم Agent مذكورًا في agents. يشير context إلى أسماء مهام سابقة فقط؛ وترفض الإشارات إلى مهام لاحقة.
إعداد YAML الكلاسيكي
المشاريع الكلاسيكية التي تُنشأ عبرcrewai create crew <name> --classic تستخدم config/tasks.yaml وفئة @CrewBase في crew.py.
يظل إعداد YAML مدعومًا للمشاريع الحالية المبنية بـ Python/YAML وللفِرق التي تفضل تعريف المهام من خلال فئة @CrewBase.
بعد إنشاء مشروع كلاسيكي، انتقل إلى ملف src/<project_name>/config/tasks.yaml وعدّل القالب ليتوافق مع متطلبات مهامك المحددة.
المتغيرات في ملفات YAML (مثل
{topic}) سيتم استبدالها بالقيم من مدخلاتك عند تشغيل الفريق:Code
tasks.yaml
CrewBase:
crew.py
يجب أن تتطابق الأسماء المستخدمة في ملفات YAML (
agents.yaml و tasks.yaml)
مع أسماء الدوال في كود Python الخاص بك.تعريف مباشر في الكود (بديل)
بدلاً من ذلك، يمكنك تعريف المهام مباشرة في كودك دون استخدام إعداد YAML:task.py
مخرجات المهمة
فهم مخرجات المهام أمر بالغ الأهمية لبناء سير عمل ذكاء اصطناعي فعال. يوفر CrewAI طريقة منظمة للتعامل مع نتائج المهام من خلال فئةTaskOutput، التي تدعم تنسيقات مخرجات متعددة ويمكن تمريرها بسهولة بين المهام.
يتم تغليف مخرجات المهمة في إطار عمل CrewAI داخل فئة TaskOutput. توفر هذه الفئة طريقة منظمة للوصول إلى نتائج المهمة، بما في ذلك تنسيقات متنوعة مثل المخرجات الخام و JSON ونماذج Pydantic.
بشكل افتراضي، سيتضمن TaskOutput المخرجات raw فقط. سيتضمن TaskOutput مخرجات pydantic أو json_dict فقط إذا تم إعداد كائن Task الأصلي مع output_pydantic أو output_json على التوالي.
خصائص مخرجات المهمة
دوال وخصائص المهمة
الوصول إلى مخرجات المهمة
بمجرد تنفيذ المهمة، يمكن الوصول إلى مخرجاتها من خلال خاصيةoutput لكائن Task. توفر فئة TaskOutput طرقًا متنوعة للتفاعل مع هذه المخرجات وعرضها.
مثال
Code
تنسيق مخرجات Markdown
يتيح معاملmarkdown تنسيق Markdown تلقائي لمخرجات المهام. عند تعيينه إلى True، ستوجّه المهمة الوكيل لتنسيق الإجابة النهائية باستخدام صيغة Markdown الصحيحة.
استخدام تنسيق Markdown
Code
markdown=True، سيتلقى الوكيل تعليمات إضافية لتنسيق المخرجات باستخدام:
#للعناوين**text**للنص العريض*text*للنص المائل-أو*للقوائم النقطية`code`للكود المضمّن
إعداد YAML مع Markdown
tasks.yaml
فوائد مخرجات Markdown
- تنسيق متسق: يضمن اتباع جميع المخرجات لاتفاقيات Markdown الصحيحة
- قابلية قراءة أفضل: محتوى منظم مع عناوين وقوائم وتأكيد
- جاهز للتوثيق: يمكن استخدام المخرجات مباشرة في أنظمة التوثيق
- توافق عبر المنصات: Markdown مدعوم عالميًا
يتم إضافة تعليمات تنسيق Markdown تلقائيًا إلى موجّه المهمة
عند تعيين
markdown=True، لذا لا تحتاج إلى تحديد متطلبات التنسيق
في وصف المهمة.تبعيات المهام والسياق
يمكن للمهام الاعتماد على مخرجات مهام أخرى باستخدام خاصيةcontext. على سبيل المثال:
Code
حراس المهام
توفر حراس المهام طريقة للتحقق من مخرجات المهام وتحويلها قبل تمريرها إلى المهمة التالية. تساعد هذه الميزة في ضمان جودة البيانات وتوفر تغذية راجعة للوكلاء عندما لا تستوفي مخرجاتهم معايير محددة. يدعم CrewAI نوعين من الحراس:- حراس قائمون على الدوال: دوال Python مع منطق تحقق مخصص، تمنحك تحكمًا كاملاً في عملية التحقق وتضمن نتائج موثوقة وحتمية.
- حراس قائمون على LLM: أوصاف نصية تستخدم LLM الخاص بالوكيل للتحقق من المخرجات بناءً على معايير لغة طبيعية. مثالية لمتطلبات التحقق المعقدة أو الذاتية.
الحراس القائمون على الدوال
لإضافة حارس قائم على الدوال إلى مهمة، قدم دالة تحقق من خلال معاملguardrail:
Code
الحراس القائمون على LLM (أوصاف نصية)
بدلاً من كتابة دوال تحقق مخصصة، يمكنك استخدام أوصاف نصية تستفيد من التحقق القائم على LLM. عندما تقدم سلسلة نصية لمعاملguardrail أو guardrails، ينشئ CrewAI تلقائيًا LLMGuardrail يستخدم LLM الخاص بالوكيل للتحقق من المخرجات بناءً على وصفك.
المتطلبات:
- يجب أن يكون للمهمة وكيل (
agent) مُعيّن (يستخدم الحارس LLM الخاص بالوكيل) - قدم سلسلة نصية واضحة ووصفية تشرح معايير التحقق
Code
- منطق التحقق المعقد الذي يصعب التعبير عنه برمجيًا
- المعايير الذاتية مثل النبرة والأسلوب أو تقييمات الجودة
- متطلبات اللغة الطبيعية التي يسهل وصفها أكثر من برمجتها
- تحليل مخرجات المهمة مقابل وصفك
- إعادة
(True, output)إذا امتثلت المخرجات للمعايير - إعادة
(False, feedback)مع تغذية راجعة محددة إذا فشل التحقق
Code
حراس متعددون
يمكنك تطبيق حراس متعددين على مهمة باستخدام معاملguardrails. تُنفَّذ الحراس المتعددون بالتسلسل، حيث يتلقى كل حارس المخرجات من السابق. يتيح لك هذا سلسلة خطوات التحقق والتحويل.
يقبل معامل guardrails:
- قائمة من دوال الحراس أو أوصاف نصية
- حارس واحد (دالة أو سلسلة نصية) (مثل
guardrail)
guardrails، فإنه يأخذ الأولوية على guardrail. سيتم تجاهل معامل guardrail عند تعيين guardrails.
Code
validate_word_countيتحقق من عدد الكلماتvalidate_no_profanityيتحقق من اللغة غير الملائمة (باستخدام المخرجات من الخطوة 1)format_outputينسّق النتيجة النهائية (باستخدام المخرجات من الخطوة 2)
guardrail_max_retries مرة.
مزج الحراس القائمين على الدوال و LLM:
يمكنك الجمع بين الحراس القائمين على الدوال والنصية في نفس القائمة:
Code
متطلبات دالة الحارس
-
توقيع الدالة:
- يجب أن تقبل معاملًا واحدًا بالضبط (مخرجات المهمة)
- يجب أن تُعيد tuple من
(bool, Any) - يُوصى بتلميحات الأنواع لكنها اختيارية
-
قيم الإعادة:
- عند النجاح: تُعيد tuple من
(bool, Any). مثال:(True, validated_result) - عند الفشل: تُعيد tuple من
(bool, str). مثال:(False, "Error message explain the failure")
- عند النجاح: تُعيد tuple من
أفضل ممارسات معالجة الأخطاء
- استجابات أخطاء منظمة:
Code
-
فئات الأخطاء:
- استخدم رموز خطأ محددة
- ضمّن السياق ذا الصلة
- قدم تغذية راجعة قابلة للتنفيذ
- سلسلة التحقق:
Code
التعامل مع نتائج الحارس
عندما يُعيد حارس(False, error):
- يتم إرسال الخطأ إلى الوكيل
- يحاول الوكيل إصلاح المشكلة
- تتكرر العملية حتى:
- يُعيد الحارس
(True, result) - يتم الوصول إلى الحد الأقصى للمحاولات (
guardrail_max_retries)
- يُعيد الحارس
Code
الحصول على مخرجات منظمة ومتسقة من المهام
من المهم أيضًا ملاحظة أن مخرجات المهمة الأخيرة في الفريق
تصبح المخرجات النهائية للفريق نفسه.
استخدام output_pydantic
تتيح لك خاصية output_pydantic تحديد نموذج Pydantic يجب أن تتوافق معه مخرجات المهمة. هذا يضمن أن المخرجات ليست منظمة فحسب، بل تم التحقق منها وفقًا لنموذج Pydantic.
إليك مثال يوضح كيفية استخدام output_pydantic:
Code
- يتم تعريف نموذج Pydantic Blog مع حقلي title و content.
- تستخدم المهمة task1 خاصية output_pydantic لتحديد أن مخرجاتها يجب أن تتوافق مع نموذج Blog.
- بعد تنفيذ الفريق، يمكنك الوصول إلى المخرجات المنظمة بعدة طرق كما هو موضح.
شرح الوصول إلى المخرجات
- الفهرسة بأسلوب القاموس: يمكنك الوصول مباشرة إلى الحقول باستخدام result[“field_name”]. يعمل هذا لأن فئة CrewOutput تنفذ دالة getitem.
- مباشرة من نموذج Pydantic: الوصول إلى الخصائص مباشرة من كائن result.pydantic.
- باستخدام دالة to_dict(): تحويل المخرجات إلى قاموس والوصول إلى الحقول.
- طباعة الكائن بالكامل: ببساطة اطبع كائن result لرؤية المخرجات المنظمة.
استخدام output_json
تتيح لك خاصية output_json تحديد المخرجات المتوقعة بتنسيق JSON. هذا يضمن أن مخرجات المهمة هي هيكل JSON صالح يمكن تحليله واستخدامه بسهولة في تطبيقك.
إليك مثال يوضح كيفية استخدام output_json:
Code
- يتم تعريف نموذج Pydantic Blog مع حقلي title و content، الذي يُستخدم لتحديد هيكل مخرجات JSON.
- تستخدم المهمة task1 خاصية output_json للإشارة إلى أنها تتوقع مخرجات JSON متوافقة مع نموذج Blog.
- بعد تنفيذ الفريق، يمكنك الوصول إلى مخرجات JSON المنظمة بطريقتين كما هو موضح.
شرح الوصول إلى المخرجات
- الوصول إلى الخصائص باستخدام الفهرسة بأسلوب القاموس: يمكنك الوصول إلى الحقول مباشرة باستخدام result[“field_name”]. هذا ممكن لأن فئة CrewOutput تنفذ دالة getitem، مما يتيح لك معاملة المخرجات كقاموس. في هذا الخيار، نسترد title و content من النتيجة.
- طباعة كائن Blog بالكامل: بطباعة result، تحصل على التمثيل النصي لكائن CrewOutput. نظرًا لأن دالة str منفذة لإعادة مخرجات JSON، سيعرض هذا المخرجات الكاملة كسلسلة منسقة تمثل كائن Blog.
باستخدام output_pydantic أو output_json، تضمن أن مهامك تنتج مخرجات بتنسيق متسق ومنظم، مما يسهّل معالجة البيانات واستخدامها داخل تطبيقك أو عبر مهام متعددة.
دمج الأدوات مع المهام
استفد من أدوات CrewAI Toolkit و LangChain Tools لتحسين أداء المهام وتفاعل الوكلاء.إنشاء مهمة بأدوات
Code
الإشارة إلى مهام أخرى
في CrewAI، يتم تمرير مخرجات مهمة واحدة تلقائيًا إلى المهمة التالية، لكن يمكنك تحديد مخرجات مهام بعينها، بما في ذلك عدة مهام، لاستخدامها كسياق لمهمة أخرى. هذا مفيد عندما تكون لديك مهمة تعتمد على مخرجات مهمة أخرى لا يتم تنفيذها مباشرة بعدها. يتم ذلك من خلال خاصيةcontext للمهمة:
Code
التنفيذ غير المتزامن
يمكنك تعريف مهمة ليتم تنفيذها بشكل غير متزامن. هذا يعني أن الفريق لن ينتظر اكتمالها للمتابعة مع المهمة التالية. هذا مفيد للمهام التي تستغرق وقتًا طويلاً، أو التي ليست حاسمة لتنفيذ المهام التالية. يمكنك بعد ذلك استخدام خاصيةcontext لتحديد في مهمة مستقبلية أنها يجب أن تنتظر اكتمال مخرجات المهمة غير المتزامنة.
Code
آلية دالة الاسترجاع
يتم تنفيذ دالة الاسترجاع بعد اكتمال المهمة، مما يتيح تشغيل إجراءات أو إشعارات بناءً على نتيجة المهمة.Code
الوصول إلى مخرجات مهمة محددة
بمجرد انتهاء الفريق من التشغيل، يمكنك الوصول إلى مخرجات مهمة محددة باستخدام خاصيةoutput لكائن المهمة:
Code
آلية تجاوز الأدوات
تحديد الأدوات في مهمة يتيح التكيف الديناميكي لقدرات الوكيل، مما يؤكد مرونة CrewAI.آليات معالجة الأخطاء والتحقق
أثناء إنشاء المهام وتنفيذها، توجد آليات تحقق معينة لضمان متانة وموثوقية خصائص المهمة. تشمل على سبيل المثال لا الحصر:- ضمان تعيين نوع مخرجات واحد فقط لكل مهمة للحفاظ على توقعات مخرجات واضحة.
- منع التعيين اليدوي لخاصية
idللحفاظ على سلامة نظام المعرّفات الفريدة.
إنشاء المجلدات عند حفظ الملفات
يتحكم معاملcreate_directory فيما إذا كان يجب على CrewAI إنشاء المجلدات تلقائيًا عند حفظ مخرجات المهام في ملفات. هذه الميزة مفيدة بشكل خاص لتنظيم المخرجات وضمان هيكلة مسارات الملفات بشكل صحيح، خاصة عند العمل مع تسلسلات مشاريع معقدة.
السلوك الافتراضي
بشكل افتراضي،create_directory=True، مما يعني أن CrewAI سينشئ تلقائيًا أي مجلدات مفقودة في مسار ملف المخرجات:
Code
تعطيل إنشاء المجلدات
إذا كنت تريد منع الإنشاء التلقائي للمجلدات والتأكد من وجود المجلد مسبقًا، عيّنcreate_directory=False:
Code
إعداد YAML
يمكنك أيضًا إعداد هذا السلوك في تعريفات مهام YAML:tasks.yaml
حالات الاستخدام
إنشاء المجلدات تلقائيًا (create_directory=True):
- بيئات التطوير والنماذج الأولية
- إنشاء تقارير ديناميكية مع مجلدات قائمة على التاريخ
- سير عمل آلي حيث قد يختلف هيكل المجلدات
- تطبيقات متعددة المستأجرين مع مجلدات خاصة بالمستخدمين
create_directory=False):
- بيئات الإنتاج مع ضوابط نظام ملفات صارمة
- التطبيقات الحساسة أمنيًا حيث يجب إعداد المجلدات مسبقًا
- الأنظمة ذات متطلبات أذونات محددة
- بيئات الامتثال حيث يتم مراقبة إنشاء المجلدات
معالجة الأخطاء
عندما يكونcreate_directory=False والمجلد غير موجود، سيرفع CrewAI خطأ RuntimeError:
Code