Explanation
How checkpointing works: events, storage, and inheritance.
Tutorial
A 5-minute walkthrough: run, interrupt, resume.
How-to guides
Task-focused recipes for common workflows.
Reference
CheckpointConfig, events, providers, and CLI.Explanation
What a checkpoint is
A checkpoint captures everything CrewAI needs to recreate a run mid-flight: the full state of the crew, flow, or agent — configuration, agent memory and knowledge sources, task progress, intermediate outputs, internal state and attributes — alongside the kickoff inputs, the event history up to that point, and a lineage ID that ties the checkpoint to the run it came from. Restoring rebuilds that state and continues. Completed tasks are skipped, memory and knowledge are rehydrated, and downstream work runs against the same outputs the original run produced. Forking does the same restore under a new lineage, so the new branch and the original run can write checkpoints side by side without overwriting each other.When checkpoints are written
Checkpointing is event-driven. The runtime subscribes to events you select viaon_events and writes a checkpoint each time one fires. The default task_completed produces one checkpoint per finished task — a sensible tradeoff between granularity and disk use. Higher-frequency events like llm_call_completed are available for fine-grained recovery but write far more files.
Storage
Two providers ship with CrewAI:JsonProviderwrites one file per checkpoint. Human-readable and easy to inspect.SqliteProviderwrites to a single SQLite database. Better for high-frequency checkpointing.
max_checkpoints is set.
Auto-checkpoint writes (event-driven) are best-effort: a failed write is logged and the run continues. Manual
state.checkpoint() and state.acheckpoint() calls re-raise on failure.Inheritance model
Crew, Flow, and Agent all accept a checkpoint argument. Children inherit from their parent unless they set their own value or pass False to opt out. Enable checkpointing once on the crew and every agent participates, or selectively exclude one agent.
Tutorial: Resume a failing crew
This walkthrough takes ~5 minutes. You will run a two-task crew, kill it midway, and resume from the saved checkpoint.1
Create the crew with checkpointing enabled
2
Run it and interrupt after the first task
Ctrl+C after the first task finishes. Look in ./.checkpoints/ — a file named <timestamp>_<uuid>.json is the checkpoint.3
Resume from the checkpoint
How-to guides
Enable checkpointing with defaults
Enable checkpointing with defaults
./.checkpoints/ on every task_completed.Customize storage and frequency
Customize storage and frequency
Choose a storage provider
Choose a storage provider
Opt one agent out
Opt one agent out
Fork into a new branch
Fork into a new branch
fork() restores a checkpoint under a fresh lineage so the new run does not collide with the original.branch label is optional; one is generated if omitted.Checkpoint a Crew, Flow, or Agent
Checkpoint a Crew, Flow, or Agent
- Crew
- Flow
- Agent
task_completed.Write a checkpoint manually
Write a checkpoint manually
Register a handler on any event and call A
state.checkpoint().state argument is supplied automatically when the handler takes three parameters. See Event Listeners for the full event catalog.Browse, resume, and fork from the CLI
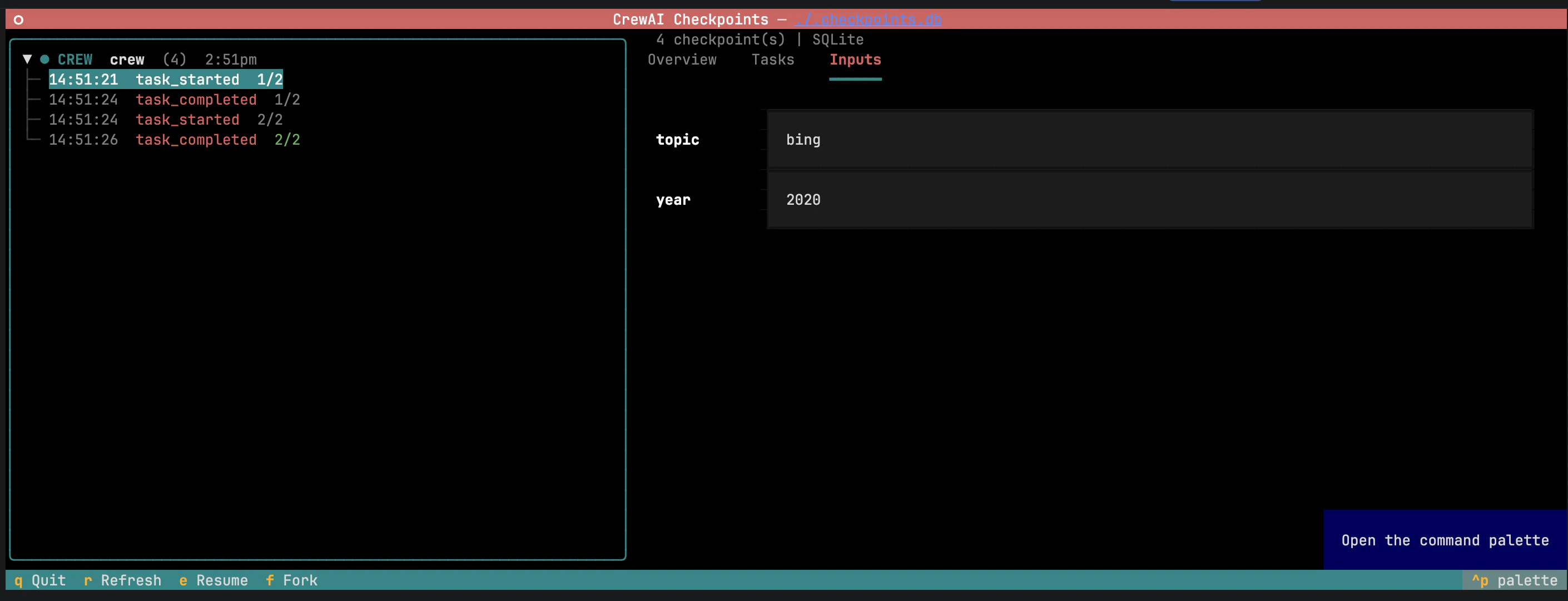
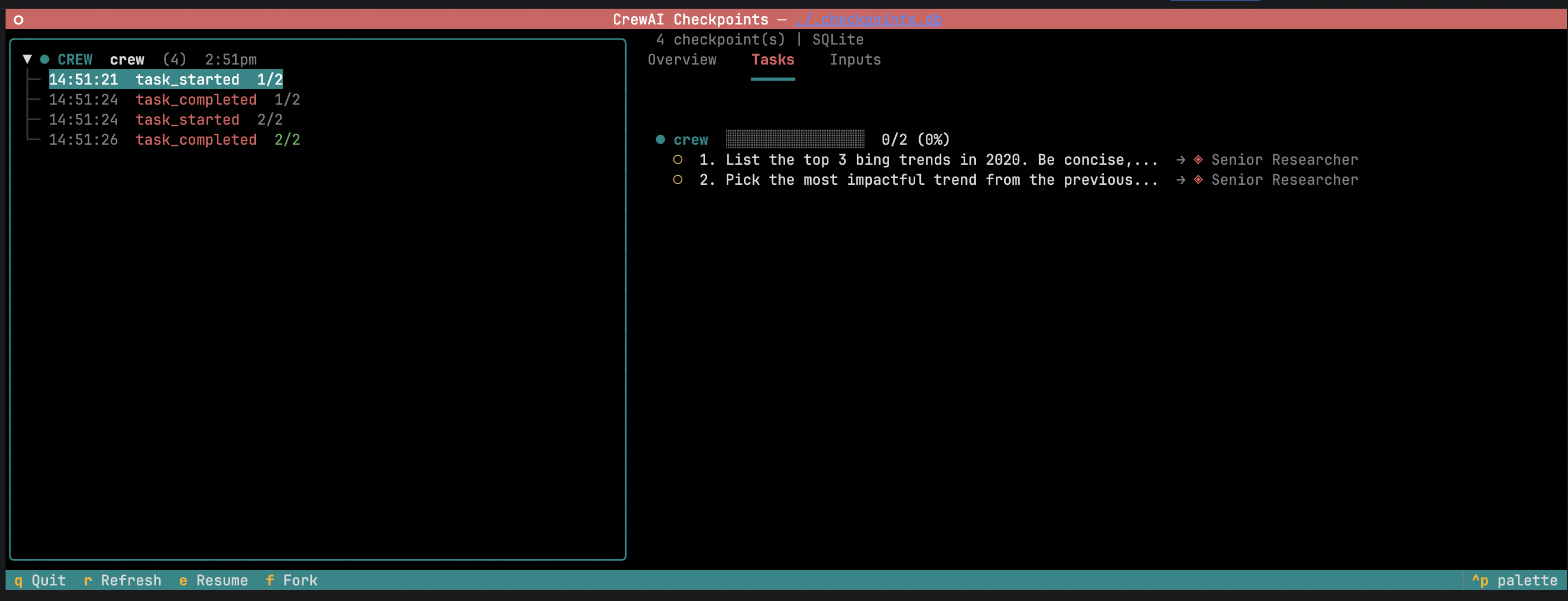
Browse, resume, and fork from the CLI
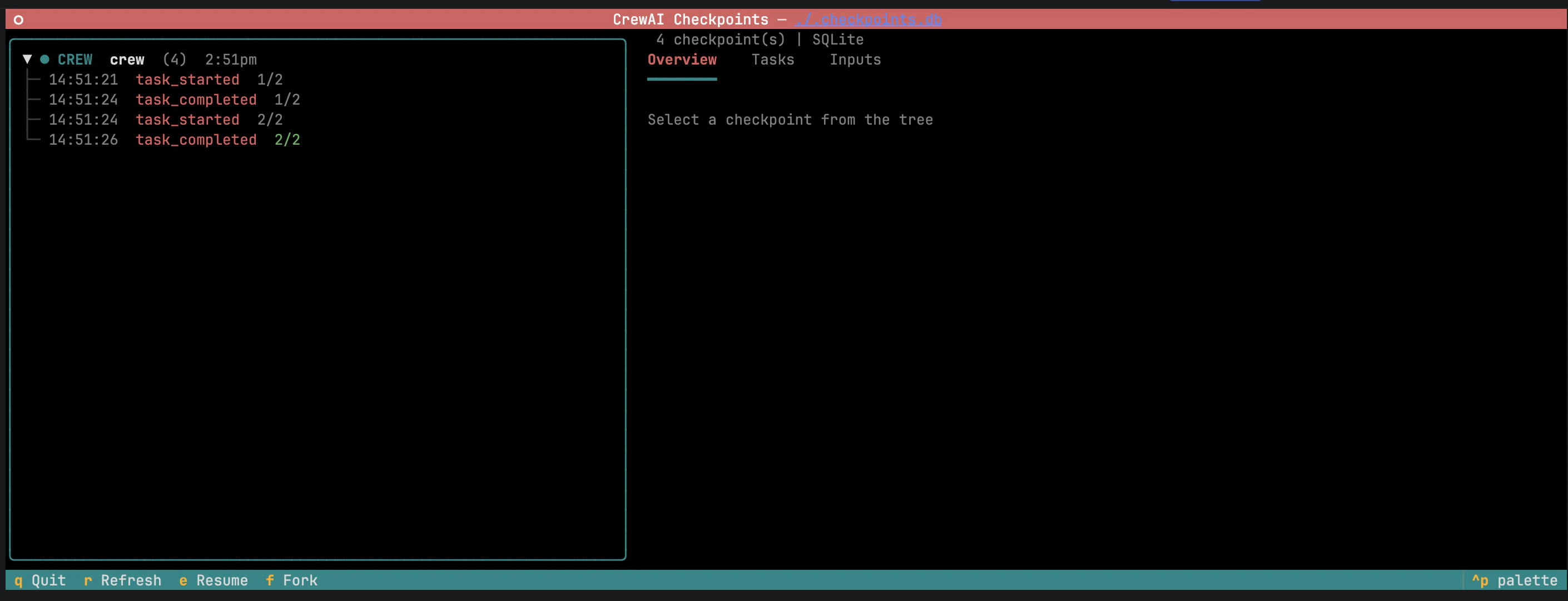
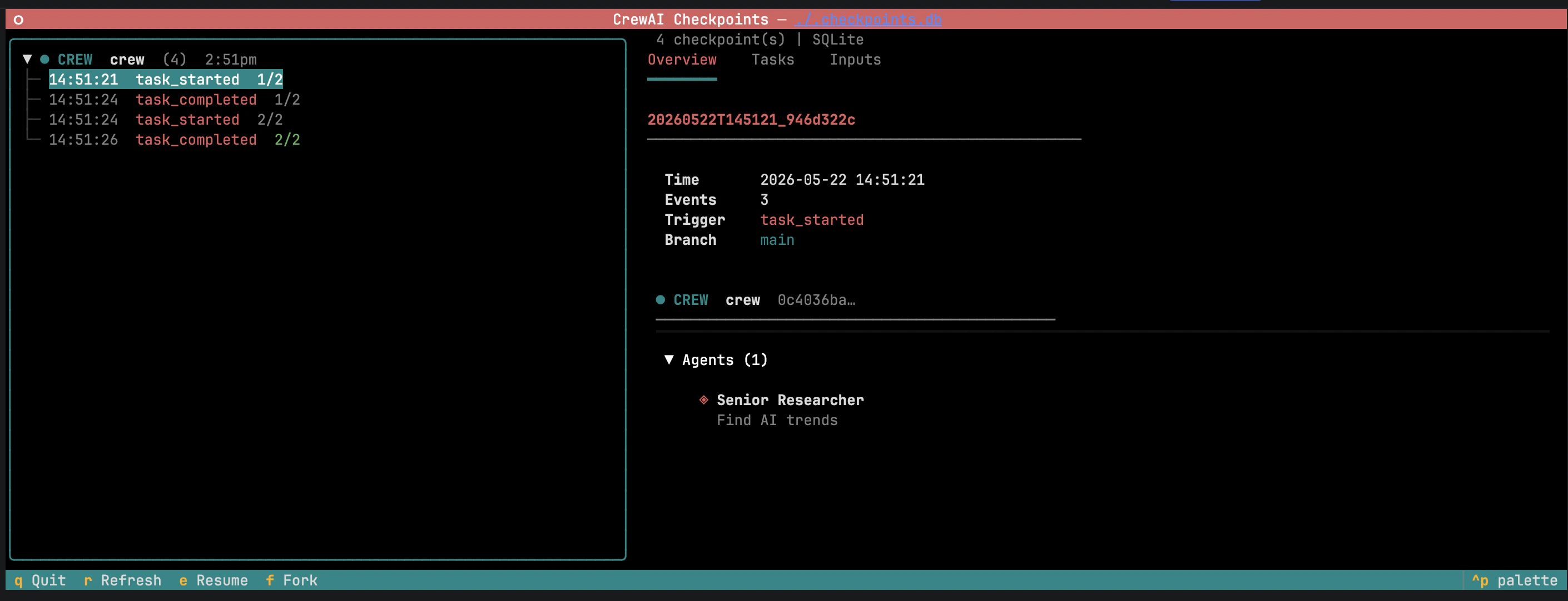
-
Inputs — original kickoff inputs, pre-filled and editable.
-
Task outputs — outputs of completed tasks. Editing an output and hitting Fork invalidates downstream tasks so they re-run against the modified context.
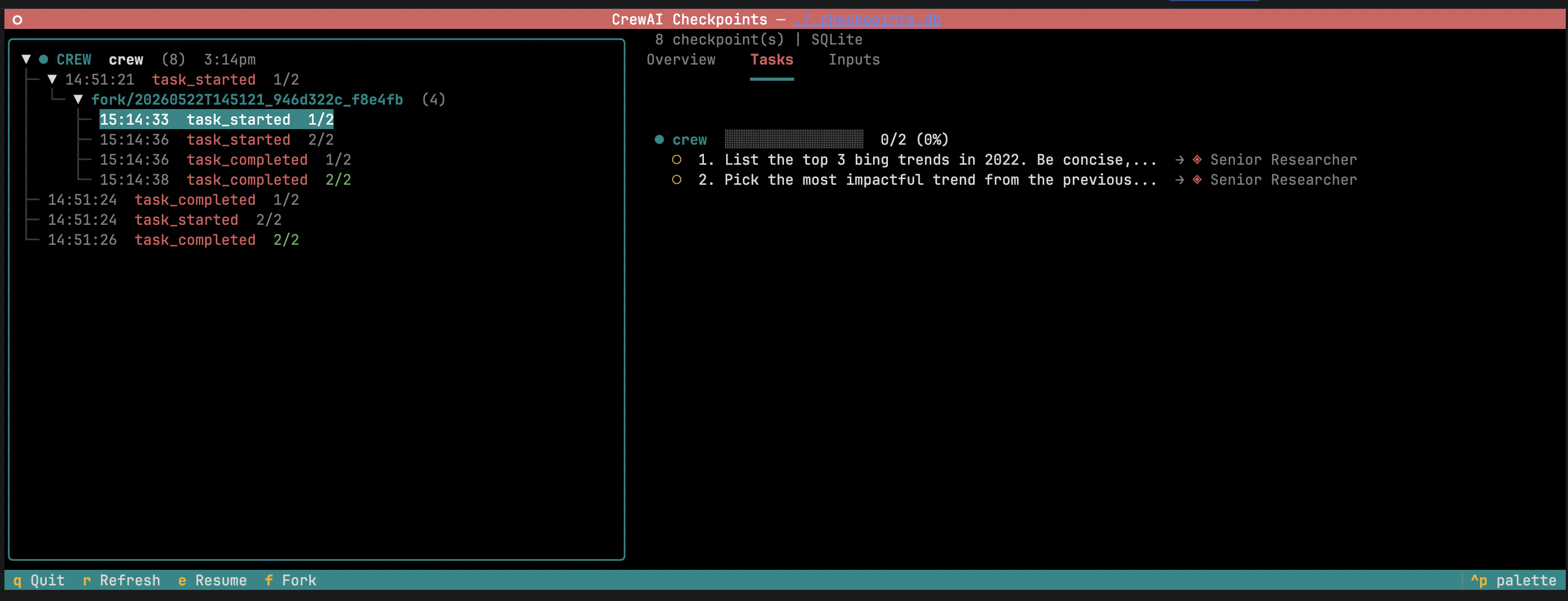
Inspect checkpoints without the TUI
Inspect checkpoints without the TUI
Reference
CheckpointConfig
Storage destination. A directory for
JsonProvider, a database file path for SqliteProvider.Event types that trigger a checkpoint.
CheckpointEventType is a Literal — your type checker will autocomplete and reject unsupported values. See event types for the full list.Storage backend. Either
JsonProvider or SqliteProvider.Maximum checkpoints to retain. Oldest are pruned after each write.
Checkpoint to restore from when passed via
from_checkpoint.checkpoint field values
Accepted by Crew, Flow, and Agent.
Inherit from parent.
Enable with defaults.
Explicit opt-out. Stops inheritance.
Custom configuration.
Event types
on_events accepts any combination of CheckpointEventType values. The default ["task_completed"] writes one checkpoint per finished task; ["*"] matches every event.
Storage providers
One file per checkpoint, named
<timestamp>_<uuid>.json inside location.Single database file at
location with WAL journaling.