CrewAI의 LLM 선택 접근 방식
처방적인 모델 추천보다는, 사고 프레임워크를 제안하여 특정 사용 사례, 제약 조건, 요구 사항에 따라 정보에 입각한 결정을 내릴 수 있도록 돕고자 합니다. LLM 환경은 빠르게 변화하고 있으며, 새로운 모델이 정기적으로 등장하고 기존 모델도 자주 업데이트되고 있습니다. 가장 중요한 것은 어떤 특정 모델이 제공되는지와 상관없이 평가를 위한 체계적인 접근법을 개발하는 것입니다.이 가이드는 LLM 환경이 빠르게 변화하고 있기 때문에 특정 모델 추천보다는 전략적
사고에 초점을 맞추고 있습니다.
빠른 결정 프레임워크
작업 분석
먼저, 작업이 실제로 무엇을 요구하는지 깊이 이해하세요. 필요한 인지 복잡성,
요구되는 추론의 깊이, 기대되는 출력 형식, 모델이 처리해야 할 맥락의 양을
고려합니다. 이러한 기본 분석이 이후의 모든 결정을 안내할 것입니다.
모델 역량 매핑
요구 사항을 이해한 후, 이를 모델의 강점에 매핑하세요. 서로 다른 모델 계열은
작업 유형에 따라 특화되어 있습니다. 일부는 추론 및 분석에 최적화되어 있고,
일부는 창의성이나 콘텐츠 생성, 또 다른 일부는 속도와 효율성에 최적화되어
있습니다.
제약 조건 고려
예산 제한, 지연 시간 요구사항, 데이터 프라이버시 필요성, 인프라 역량 등 실제
운영상의 제약 조건을 반영하세요. 이론적으로 가장 좋은 모델이 실제로는 최선의
선택이 아닐 수 있습니다.
코어 선택 프레임워크
a. Task-First Thinking
LLM을 선택할 때 가장 중요한 단계는 실제로 여러분의 작업이 무엇을 요구하는지 이해하는 것입니다. 너무 자주 팀들은 특정 요구 사항을 면밀하게 분석하지 않고, 일반적인 평판이나 벤치마크 점수를 기반으로 모델을 선택합니다. 이런 접근 방식은 단순한 작업에 비싸고 복잡한 모델을 과도하게 적용하거나, 정교한 업무에 필요한 기능이 부족한 모델을 선택하게 만들어 결과적으로 과소 성능 문제를 야기합니다.- Reasoning Complexity
- Output Requirements
- Context Needs
- Simple Tasks는 대부분의 일상적인 AI 작업을 대표하며, 기본 명령 수행, 간단한 데이터 처리, 단순한 포맷팅 작업 등을 포함합니다. 이러한 작업은 일반적으로 명확한 입력과 출력을 가지고 있으며 모호성이 거의 없습니다. 인지적 부하는 낮고, 모델은 복잡한 추론보다는 명확한 지시에 따라 움직이면 됩니다.
- Complex Tasks는 다단계 추론, 전략적 사고, 모호하거나 불완전한 정보를 처리하는 능력을 필요로 합니다. 여러 데이터 소스를 분석하거나, 포괄적 전략을 개발하거나, 더 작은 구성 요소로 분해해야 하는 문제 해결 작업 등이 이에 해당합니다. 모델은 여러 추론 단계를 거치는 동안 맥락을 유지해야 하며, 명시적으로 언급되지 않은 내용을 추론해야 할 때가 많습니다.
- Creative Tasks는 새롭고, 흥미로우며, 맥락에 적합한 콘텐츠를 생성하는 데 중점을 둔 새로운 인지적 능력을 요구합니다. 여기에는 스토리텔링, 마케팅 카피 작성, 창의적 문제 해결이 포함됩니다. 모델은 뉘앙스, 톤, 대상 청중을 이해하고, 공식적이지 않고 진정성 있고 흥미로운 콘텐츠를 제작해야 합니다.
b. 모델 역량 매핑
모델 역량을 이해하기 위해서는 마케팅 주장이나 벤치마크 점수 너머를 바라보고, 다양한 모델 구조와 학습 접근법의 근본적인 강점과 한계를 파악해야 합니다.Reasoning Models
Reasoning Models
Reasoning 모델은 복잡하고 다단계의 사고가 필요한 작업을 위해 특별히 설계된 특수 카테고리를 나타냅니다. 이러한 모델은 문제를 신중하게 분석하거나 전략적으로 계획을 세우거나 체계적으로 문제를 분해해야 하는 경우에 뛰어납니다. 일반적으로 chain-of-thought reasoning 혹은 tree-of-thought processing과 같은 기법을 사용하여 복잡한 문제를 단계별로 해결합니다.Reasoning 모델의 강점은 확장된 reasoning 체인에서 논리적 일관성을 유지하고, 복잡한 문제를 관리 가능한 구성 요소로 나눌 수 있다는 점에 있습니다. 전략적 계획, 복잡한 분석, 그리고 응답 속도보다 reasoning의 질이 더 중요한 상황에서 특히 가치가 있습니다.하지만 reasoning 모델은 속도와 비용 면에서 트레이드오프가 따르는 경우가 많습니다. 또한 그들의 고도화된 reasoning 역량이 필요 없는 창의적인 작업이나 간단한 작업에는 덜 적합할 수 있습니다. 체계적이고 단계적인 분석이 요구되는 진정한 복잡성이 관련된 작업에서 이러한 모델을 고려하십시오.
General Purpose Models
General Purpose Models
General purpose 모델은 LLM 선택에서 가장 균형 잡힌 접근 방식을 제공하며, 특정 영역에 극단적으로 특화되지 않으면서도 다양한 작업에 대해 견고한 성능을 제공합니다. 이러한 모델은 다양한 데이터셋으로 학습되었으며, 특정 도메인에서의 최고 성능보다는 다재다능함에 최적화되어 있습니다.General purpose 모델의 주요 장점은 다양한 유형의 작업에서 예측 가능한 신뢰성과 일관성입니다. 조사, 분석, 콘텐츠 제작, 데이터 처리 등 대부분의 표준 비즈니스 작업을 충분히 처리할 수 있습니다. 이로 인해 다양한 워크플로우 전반에서 일관된 성능이 필요한 팀에 매우 적합한 선택이 됩니다.General purpose 모델은 특정 도메인에서 특화된 대안들이 보여주는 최고 성능에는 미치지 않을 수 있지만, 운영의 단순성과 모델 관리의 복잡성 감소라는 이점이 있습니다. 신규 프로젝트의 시작점으로 가장 좋은 선택인 경우가 많으며, 팀이 구체적인 필요를 이해하고 나서 특화 모델로 최적화할 수 있습니다.
Fast & Efficient Models
Fast & Efficient Models
Fast and efficient 모델은 고도화된 reasoning 역량보다 속도, 비용 효율, 리소스 효율성을 우선순위에 둡니다. 이러한 모델은 빠른 응답성과 낮은 운영비용이 중요하고, 미묘한 이해나 복잡한 reasoning이 덜 요구되는 고처리량 시나리오에 최적화되어 있습니다.이러한 모델은 일상적인 운영, 간단한 데이터 처리, 함수 호출, 대용량 작업 등 인지적 요구가 비교적 단순한 시나리오에서 뛰어납니다. 많은 요청을 신속하게 처리해야 하거나 예산 제약 내에서 운영되어야 하는 애플리케이션에 특히 유용합니다.효율적인 모델에서 가장 중요한 고려사항은 그들의 역량이 귀하의 작업 요구와 일치하는지 확인하는 것입니다. 많은 일상적 작업은 효과적으로 처리할 수 있지만, Nuanced한 이해, 복잡한 reasoning, 혹은 고도화된 콘텐츠 생성이 필요한 작업에는 어려움을 겪을 수 있습니다. 정교함보다 속도와 비용이 더 중요한 명확하고 일상적인 작업에 가장 적합합니다.
Creative Models
Creative Models
Creative 모델은 콘텐츠 생성, 글쓰기 품질, 창의적 사고가 요구되는 작업에 특별히 최적화되어 있습니다. 이러한 모델은 뉘앙스, 톤, 스타일을 이해하면서도 자연스럽고 진정성 있게 느껴지는 매력적이고 맥락에 맞는 콘텐츠를 생성하는 데 뛰어납니다.Creative 모델의 강점은 다양한 대상에 맞춰 글쓰기 스타일을 조정하고, 일관된 목소리와 톤을 유지하며, 독자를 효과적으로 사로잡는 콘텐츠를 생성할 수 있다는 점입니다. 스토리텔링, 마케팅 카피, 브랜드 커뮤니케이션 등 창의성과 몰입이 주요 목적이 되는 콘텐츠 작업에서 더 우수한 성과를 보입니다.Creative 모델을 선택할 때는 단순한 텍스트 생성 능력뿐 아니라, 대상, 맥락, 목적에 대한 이해력도 함께 고려해야 합니다. 최상의 creative 모델은 특정 브랜드 목소리에 맞게 출력 내용을 조정하고, 다양한 대상 그룹을 타깃팅하며, 긴 콘텐츠에서도 일관성을 유지할 수 있습니다.
Open Source Models
Open Source Models
Open source 모델은 비용 통제, 맞춤화 가능성, 데이터 프라이버시, 배포 유연성 측면에서 독특한 이점을 제공합니다. 이러한 모델은 로컬이나 사설 인프라에서 운용이 가능하여 데이터 처리 및 모델 동작에 대해 완전한 통제권을 제공합니다.Open source 모델의 주요 이점으로는 토큰당 비용의 제거, 특정 용도에 맞춘 파인튜닝 가능성, 완전한 데이터 프라이버시, 외부 API 제공자에 대한 의존성 해소가 있습니다. 특히 엄격한 데이터 프라이버시 요구사항, 예산 제약, 특정 맞춤화 필요가 있는 조직에 매우 유용합니다.그러나 open source 모델은 효과적으로 배포 및 유지관리하기 위해 더 많은 기술 전문성이 필요합니다. 팀에서는 인프라 비용, 모델 관리 복잡성, 지속적인 모델 업데이트 및 최적화를 위한 지속적인 노력을 고려해야 합니다. 기술적 오버헤드를 감안하면 전체 소유 비용이 클라우드 기반 대안보다 높을 수 있습니다.
전략적 구성 패턴
a. 멀티-모델 접근 방식
가장 정교하게 구현된 CrewAI의 경우, 여러 개의 모델을 전략적으로 활용하여 각 agent의 역할과 요구 사항에 맞는 모델을 지정합니다. 이 접근 방식은 각 작업 유형에 가장 적합한 모델을 사용함으로써 성능과 비용을 모두 최적화할 수 있게 해줍니다. planning agent는 복잡한 전략적 사고와 다단계 분석을 처리할 수 있는 reasoning 모델을 활용할 때 이점을 얻습니다. 이 agent들은 운영의 “두뇌” 역할을 하며, 전략 수립과 다른 agent들의 작업을 조정합니다. 반면 content agent는 글의 품질과 독자 참여에 뛰어난 creative 모델을 통해 최고의 성능을 발휘합니다. 일상적인 작업과 운영을 담당하는 processing agent는 속도와 비용 효율을 우선시하는 효율적인 모델을 사용할 수 있습니다. 예시: Research and Analysis Crewb. 구성요소별 선택
- Manager LLM
- Function Calling LLM
- Agent-Specific Overrides
Manager LLM은 계층적 CrewAI 프로세스에서 중요한 역할을 하며, 여러 에이전트와 작업을 조정하는 중심점으로 작동합니다. 이 모델은 위임, 작업 우선순위 지정, 여러 동시 작업 간의 컨텍스트 유지에 뛰어나야 합니다.효과적인 Manager LLM은 올바른 위임 결정을 내리기 위한 강력한 추론 능력, 예측 가능한 조정을 보장하는 일관된 성능, 여러 에이전트의 상태를 동시에 추적하기 위한 탁월한 컨텍스트 관리가 필요합니다. 이 모델은 다양한 에이전트의 역량과 한계를 이해하고, 효율성과 품질을 최적화하기 위해 작업 할당을 최적화해야 합니다.Manager LLM은 모든 작업에 관여하기 때문에 비용 고려가 특히 중요합니다. 모델은 효과적인 조정을 위한 충분한 역량을 제공하면서도, 잦은 사용에도 비용 효율적이어야 합니다. 이는 종종 가장 정교한 모델의 높은 가격 없이도 충분한 추론 능력을 제공하는 모델을 찾는 것을 의미합니다.
작업 정의 프레임워크
a. 복잡성보다 명확성에 집중하기
CrewAI 출력의 품질을 결정하는 데 있어 모델 선택보다 효과적인 작업 정의가 더 중요한 경우가 많습니다. 잘 정의된 작업은 명확한 방향과 맥락을 제공하여 심지어 보통 수준의 모델도 좋은 성능을 낼 수 있게 해주지만, 잘못 정의된 작업은 고도화된 모델조차 만족스럽지 않은 결과를 만들 수 있습니다.효과적인 작업 설명
효과적인 작업 설명
최고의 작업 설명은 적절한 세부 정보 제공과 명확성 유지를 균형 있게 조화시킵니다. 작업의 구체적인 목표를 성공이 어떤 모습인지에 대한 모호함 없이 명확하게 정의해야 하며, 접근 방식이나 방법론을 충분히 설명하여 에이전트가 어떻게 진행해야 하는지 이해할 수 있도록 해야 합니다.효과적인 작업 설명은 에이전트가 더 넓은 목적과 그들이 반드시 지켜야 할 제한사항을 이해할 수 있도록 관련 맥락 및 제약 조건을 포함합니다. 복잡한 작업을 체계적으로 실행할 수 있는 집중된 단계로 분할하여, 여러 측면이 뒤섞이고 접근하기 어려운 압도적인 목표로 제시하지 않습니다.일반적인 실수로는 목표가 너무 모호하다거나, 필요한 맥락을 제공하지 않는다거나, 성공 기준이 불분명하다거나, 관련 없는 여러 작업을 하나의 설명으로 결합하는 경우가 있습니다. 목표는 단일의 명확한 목적에 집중하며, 에이전트가 성공할 수 있을 정도로 충분한 정보를 제공하는 것입니다.
예상 산출물 가이드라인
예상 산출물 가이드라인
예상 산출물 가이드라인은 작업 정의와 에이전트 간의 계약 역할을 하며, 산출물이 어떤 모습이어야 하며 어떻게 평가될 것인지 명확하게 지정합니다. 이러한 가이드라인은 필요한 형식과 구조뿐만 아니라 산출물이 완전하다고 간주되기 위해 반드시 포함되어야 하는 핵심 요소도 설명해야 합니다.최고의 산출물 가이드라인은 품질 지표에 대한 구체적인 예시를 제공하고, 완료 기준을 에이전트와 인간 평가자 모두가 작업의 성공적 완료 여부를 평가할 수 있을 만큼 명확하게 정의합니다. 이는 모호함을 줄이고 여러 작업 실행 간 일관된 결과를 보장하는 데 도움이 됩니다.어떤 작업에나 적용할 수 있을 정도로 일반적인 산출물 설명, 에이전트가 구조를 추측해야 하는 형식 명세 누락, 평가가 어려운 불분명한 품질 기준, 에이전트가 기대치를 이해하도록 도와주는 예시 또는 템플릿 미제공 등은 피해야 합니다.
b. 작업 순서 지정 전략
- 순차적 의존성
- 병렬 실행
작업이 이전 산출물에 기반을 두거나, 정보가 한 작업에서 다른 작업으로 흐르거나, 품질이 선행 작업의 완료에 의존할 때 순차적 작업 의존성이 필수적입니다. 이 접근 방식은 각 작업이 성공적으로 수행되는 데 필요한 정보와 맥락에 접근할 수 있도록 보장합니다.순차적 의존성을 효과적으로 구현하기 위해서는 context 파라미터를 사용하여 관련 작업을 연쇄시키고, 작업의 진행을 통해 점진적으로 복잡성을 구축하며, 각 작업이 다음 작업에 의미 있는 입력값이 될 수 있는 산출물을 생성하도록 해야 합니다. 목표는 의존된 작업 간의 논리적 흐름을 유지하면서 불필요한 병목을 피하는 것입니다.순차적 의존성은 한 작업에서 다른 작업으로 명확한 논리적 진행이 있고, 한 작업의 산출물이 다음 작업의 품질이나 실행 가능성을 실제로 향상시킬 때 가장 효과적입니다. 그러나 적절히 관리되지 않을 경우 병목 현상이 발생할 수 있으니, 반드시 진정으로 필요한 의존성과 단순히 편의상 설정된 의존성을 구분해야 합니다.
LLM 성능을 위한 에이전트 구성 최적화
a. 역할 기반 LLM 선택
에이전트 역할의 구체성은 최적의 성능을 위해 어떤 LLM의 능력이 가장 중요한지를 직접적으로 결정합니다. 이는 에이전트의 책임에 정확히 맞는 모델 강점을 연결할 수 있는 전략적 기회를 만듭니다. 일반 역할 vs. 구체적 역할이 LLM 선택에 미치는 영향: 역할을 정의할 때 에이전트가 다룰 작업에 가장 가치 있는 특정 도메인 지식, 작업 방식, 의사결정 프레임워크를 고려하세요. 역할 정의가 더 구체적이고 상황에 맞을수록 모델이 그 역할을 효과적으로 구현할 수 있습니다.- “Research Analyst” → 복잡한 분석을 위한 reasoning 모델 (GPT-4o, Claude Sonnet)
- “Content Editor” → 작문 품질을 위한 creative 모델 (Claude, GPT-4o)
- “Data Processor” → 구조화된 태스크를 위한 효율적인 모델 (GPT-4o-mini, Gemini Flash)
- “API Coordinator” → 도구 사용을 위한 function-calling 최적화 모델 (GPT-4o, Claude)
b. 모델 컨텍스트 증폭기로서의 백스토리
전략적으로 구성된 백스토리는 도메인 특화 컨텍스트를 제공하여 일반적인
프롬프트로는 달성할 수 없는 수준으로 선택한 LLM의 효율성을 획기적으로
높여줍니다.
- 도메인 경험: “10년 이상의 엔터프라이즈 SaaS 영업 경력”
- 특정 전문성: “시리즈 B+ 라운드의 기술 실사 전문”
- 업무 스타일: “명확한 문서화와 데이터 기반 의사결정을 선호”
- 품질 기준: “출처 인용과 분석 근거 제시를 중시”
c. 총체적 Agent-LLM 최적화
가장 효과적인 agent 구성은 역할 특이성, 백스토리 깊이, 그리고 LLM 선택 간의 시너지를 창출합니다. 각 요소는 서로를 강화하여 모델 성능을 극대화합니다. 최적화 프레임워크:- ✅ 역할 특이성: 명확한 도메인과 책임
- ✅ LLM 적합도: 모델의 강점이 역할 요구사항과 일치
- ✅ 백스토리 깊이: LLM이 활용할 수 있는 도메인 맥락 제공
- ✅ 도구 통합: 도구가 agent의 특수 기능을 지원
- ✅ 파라미터 튜닝: 온도 및 설정이 역할에 최적화
실무 구현 체크리스트
전략적 프레임워크를 반복하는 대신, CrewAI에서 LLM 선택 결정을 실행하는 데 사용할 수 있는 전술적 체크리스트를 제공합니다:현재 셋업 점검
검토할 사항:
- 모든 agent가 기본적으로 동일한 LLM을 사용하고 있습니까?
- 어떤 agent가 가장 복잡한 reasoning 작업을 처리합니까?
- 어떤 agent가 주로 데이터 처리 또는 포매팅을 담당합니까?
- 도구에 크게 의존하는 agent가 있습니까?
엔터프라이즈 테스트로 검증
agent를 프로덕션에 배포한 후:
- CrewAI AMP platform을 활용하여 모델 선택을 A/B 테스트하세요
- 실제 입력으로 여러 번 반복 테스트하여 일관성과 성능을 측정하세요
- 최적화된 셋업 전반의 비용과 성능을 비교하세요
- 팀과 결과를 공유하여 협업 의사결정을 지원하세요
다양한 모델 유형을 사용할 시기
- Reasoning Models
- Creative Models
- Efficient Models
- Open Source Models
reasoning 모델은 진정한 다단계 논리적 사고, 전략적 계획 수립, 또는 체계적인 분석이 필요한 고수준의 의사결정이 요구되는 작업에서 필수적입니다. 이러한 모델은 문제를 구성 요소로 분해하고 체계적으로 분석해야 할 때, 단순한 패턴 매칭이나 지시 사항 이행만으로는 해결할 수 없는 경우에 뛰어난 성능을 발휘합니다.예를 들어, 비즈니스 전략 개발, 여러 출처에서 인사이트를 도출해야 하는 복잡한 데이터 분석, 각 단계가 이전 분석을 기반으로 해야 하는 다단계 문제 해결, 다양한 변수 및 이들의 상호작용을 고려해야 하는 전략적 계획 수립 업무에 reasoning 모델을 고려해 보세요.그러나 reasoning 모델은 일반적으로 더 높은 비용과 느린 응답 시간을 수반하므로, 복잡한 사고가 필요한 작업에서 실질적인 가치를 제공할 때에만 사용하는 것이 좋으며, 복잡한 reasoning이 필요하지 않은 단순한 작업에는 권장되지 않습니다.
CrewAI 모델 선택에서 흔히 발생하는 실수
‘하나의 모델로 모두 해결’ 함정
‘하나의 모델로 모두 해결’ 함정
문제점: 각 agent의 역할과 책임과 상관없이 모든 agent에 동일한 LLM을 사용하는 것. 대부분 기본적으로 선택되는 접근 방식이지만, 최적의 결과가 나오지 않는 경우가 많음.실제 예시: 전략 기획 매니저와 데이터 추출 agent 모두에게 GPT-4o를 사용하는 경우. 매니저는 높은 추론 성능이 필요해 프리미엄 모델이 적합하나, 데이터 추출 업무는 저렴한 GPT-4o-mini만으로도 충분한 성능을 낼 수 있음.CrewAI 솔루션: agent별 LLM 설정을 활용해, agent의 역할에 맞는 모델 역량을 매칭:
Crew 수준과 Agent 수준 LLM 계층 혼동
Crew 수준과 Agent 수준 LLM 계층 혼동
문제점: CrewAI의 LLM 계층 구조(crew LLM, manager LLM, agent LLM)를 이해하지 못해 설정이 충돌하거나 적절히 조정되지 않음.실제 예시: crew에는 Claude를, agent에는 GPT 모델을 설정해 일관성 없는 동작과 불필요한 모델 전환 오버헤드가 발생하는 경우.CrewAI 솔루션: LLM 계층 구조를 전략적으로 설계:
함수 호출 모델 미스매치
함수 호출 모델 미스매치
문제점: 기능 위주(함수 호출, 툴 활용 등) CrewAI workflow에서 필요한 함수 호출 성능을 무시한 채, 일반적인 모델 특성(예: 창의성)만을 보고 모델을 선택하는 실수.실제 예시: 주로 API 호출, 검색 툴, 구조화 데이터 처리가 필요한 agent에 창의성 위주의 모델을 선택해, 도구 파라미터 추출과 신뢰성 있는 함수 호출에 실패하는 경우.CrewAI 솔루션: 도구 중심 agent는 함수 호출 성능 위주로 모델을 선택:
테스트 없는 조기 최적화
테스트 없는 조기 최적화
문제점: 실제 CrewAI workflow 및 업무 테스트 없이 이론상 성능만으로 복잡하게 모델을 선정하고 구성하는 실수.실제 예시: 업무 유형별로 복잡한 모델 전환 로직을 구현하지만, 실제 성능 향상이 운영 복잡성을 정당화하지 못하는 경우.CrewAI 솔루션: 단순한 구조로 시작해서, 실제 성능 데이터를 바탕으로 점진적으로 최적화:
컨텍스트·메모리 한계 간과
컨텍스트·메모리 한계 간과
문제점: 모델의 컨텍스트 윈도(window)와 CrewAI의 메모리, agent 간 컨텍스트 공유 방식을 고려하지 않는 실수.실제 예시: 여러 차례 반복되는 업무나 agent 간 활발한 소통이 필요한 crew에 대화 내역을 오래 유지해야 하는데, 짧은 컨텍스트 모델을 사용한 경우.CrewAI 솔루션: crew의 소통 패턴에 맞춰 컨텍스트 처리 능력을 갖춘 모델을 선택.
테스트 및 반복 전략
간단하게 시작하기
신뢰할 수 있고, 잘 알려져 있으며, 널리 지원되는 범용 모델로 시작하세요.
이것은 최적화된 특수한 필요에 집중하기 전에 귀하의 특정 요구사항과 성능
기대치를 이해할 수 있는 안정적인 기초를 제공합니다.
중요한 것 측정하기
일반적인 벤치마크에만 의존하지 말고, 귀하의 특정 사용 사례와 비즈니스 요구에
부합하는 지표를 개발하세요. 이론적 성능 지표가 아니라 성공에 직접적으로
영향을 미치는 결과 측정에 집중하세요.
결과에 기반한 반복
이론적 고려사항이나 일반적인 권장사항이 아니라, 귀하의 특정 상황에서 관찰된
성능에 따라 모델을 변경하세요. 실제 성능은 벤치마크 결과나 일반적인 평판과는
크게 다를 수 있습니다.
엔터프라이즈급 모델 검증
LLM 선택을 최적화하고자 하는 팀을 위해 CrewAI AMP 플랫폼은 기본적인 CLI 테스트를 훨씬 능가하는 정교한 테스트 기능을 제공합니다. 이 플랫폼은 데이터 기반의 LLM 전략 의사결정을 지원하는 종합적인 모델 평가를 가능하게 합니다.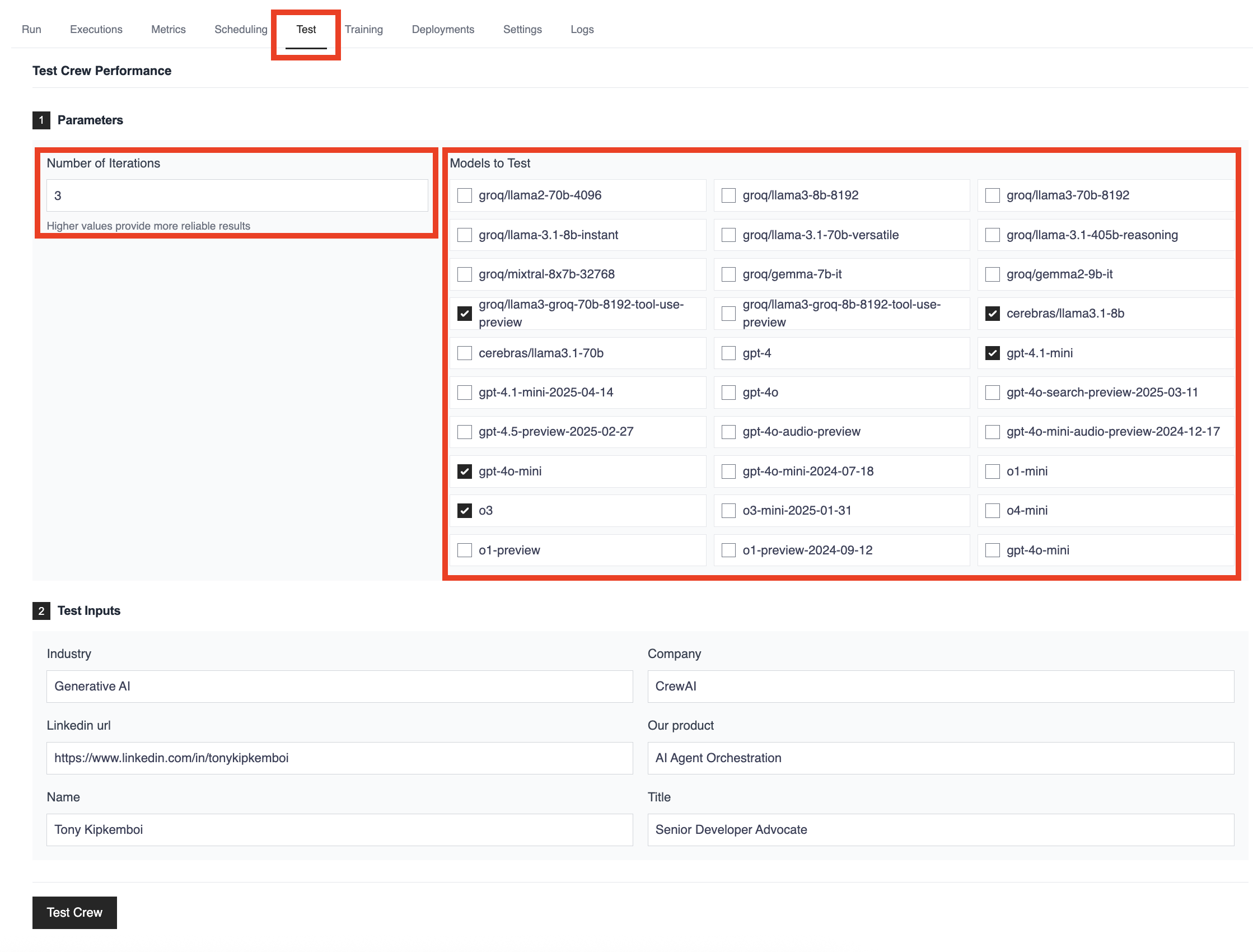
- 다중 모델 비교: 동일한 작업과 입력에 대해 여러 LLM을 동시에 테스트할 수 있습니다. GPT-4o, Claude, Llama, Groq, Cerebras 및 기타 선도적인 모델의 성능을 병렬로 비교하여 특정 사용 사례에 가장 적합한 모델을 식별할 수 있습니다.
- 통계적 엄밀성: 일관된 입력값으로 여러 번 테스트를 구성하여 신뢰성과 성능 편차를 측정할 수 있습니다. 이를 통해 단순히 잘하는 모델이 아닌, 여러 번 실행해도 안정적으로 동작하는 모델을 식별할 수 있습니다.
- 실제 환경 검증: 합성 벤치마크가 아닌 실제 crew 입력값과 시나리오를 사용할 수 있습니다. 플랫폼을 통해 산업 환경, 회사 정보, 실제 사용 사례 등 특정 맥락에 맞는 테스트가 가능하여 보다 정확한 평가가 이뤄집니다.
- 종합 분석 도구: 테스트한 모든 모델의 세부 성능 지표, 실행 시간, 비용 분석을 확인할 수 있습니다. 이로써 모델의 일반적인 평판이나 이론적 능력에 기대지 않고 데이터 기반으로 의사결정을 내릴 수 있습니다.
- 팀 협업: 팀 내에서 테스트 결과와 모델 성능 데이터를 공유할 수 있어, 협업적 의사결정과 프로젝트 전반에서 일관된 모델 선택 전략을 수립할 수 있습니다.
Enterprise 플랫폼은 모델 선택을 단순한 추측이 아닌 데이터 기반 프로세스로
혁신하여, 본 가이드의 원칙을 실제 사용 사례와 요구 사항에 맞게 검증할 수
있도록 해줍니다.
주요 원칙 요약
작업 중심 선택
이론적 능력이나 일반적인 평판이 아니라, 작업에 실제로 필요한 것에 따라 모델을 선택하세요.
능력 일치
최적의 성능을 위해 모델의 강점을 agent의 역할 및 책임과 일치시키세요.
전략적 일관성
관련 구성 요소와 워크플로 전반에 걸쳐 일관된 모델 선택 전략을 유지하세요.
실용적 테스트
벤치마크에만 의존하지 말고 실제 사용을 통해 선택을 검증하세요.
반복적 개선
단순하게 시작하고 실제 성능과 필요에 따라 최적화하세요.
운영적 균형
성능 요구사항과 비용 및 복잡성 제약을 균형 있게 맞추세요.
기억하세요: 최고의 LLM 선택이란 운영상의 제약 내에서 일관되게 필요한 결과를
제공하는 모델입니다. 먼저 요구사항을 정확히 이해하는 데 집중한 후, 그에 가장
잘 맞는 모델을 선택하세요.
현재 모델 현황 (2025년 6월)
카테고리별 주요 모델
아래 표는 다양한 카테고리에서 현재 최고의 성능을 보이는 대표적인 모델들을 보여주며, CrewAI 에이전트에 적합한 모델 선택에 대한 가이드를 제공합니다:이 표와 지표는 각 카테고리에서 선별된 주요 모델을 보여주기 위한 것으로, 전체를
포괄하지 않습니다. 여기 소개되지 않은 훌륭한 모델들도 많이 존재합니다. 이 표의
목적은 완전한 목록을 제공하는 것이 아니라, 어떤 능력을 갖춘 모델을 찾아야
하는지 예시를 제시하는 것입니다.
- Reasoning & Planning
- Coding & Technical
- Speed & Efficiency
- Balanced Performance
매니저 LLM 및 복잡한 분석에 최적
이 모델들은 다단계 reasoning에 뛰어나며, 전략을 개발하거나 다른 에이전트를 조정하거나 복잡한 정보를 분석해야 하는 에이전트에 이상적입니다.
| Model | Intelligence Score | Cost ($/M tokens) | Speed | Best Use in CrewAI |
|---|---|---|---|---|
| o3 | 70 | $17.50 | 빠름 | 복잡한 멀티 에이전트 조정용 매니저 LLM |
| Gemini 2.5 Pro | 69 | $3.44 | 빠름 | 전략 기획 에이전트, 연구 조정 |
| DeepSeek R1 | 68 | $0.96 | 보통 | 예산을 중시하는 팀을 위한 비용 효율적 reasoning |
| Claude 4 Sonnet | 53 | $6.00 | 빠름 | 세밀한 이해가 필요한 분석 에이전트 |
| Qwen3 235B (Reasoning) | 62 | $2.63 | 보통 | reasoning 작업을 위한 오픈소스 대안 |
현재 모델을 위한 선택 프레임워크
High-Performance Crews
High-Performance Crews
퍼포먼스가 우선 순위일 때: 매니저 LLM 또는 중요한 에이전트 역할에는 o3, Gemini 2.5 Pro, Claude 4 Sonnet과 같은 최상위 모델을 사용하세요. 이 모델들은 복잡한 reasoning 및 coordination에 탁월하지만 비용이 더 높습니다.전략: 프리미엄 모델이 전략적 사고를 담당하고, 효율적인 모델이 일상적 operation을 처리하는 멀티 모델 접근법을 구현하세요.
Cost-Conscious Crews
Cost-Conscious Crews
예산이 주요 제약일 때: DeepSeek R1, Llama 4 Scout, Gemini 2.0 Flash와 같은 모델에 집중하세요. 이 모델들은 훨씬 낮은 비용으로 강력한 퍼포먼스를 제공합니다.전략: 대부분의 에이전트에는 비용 효율이 높은 모델을 사용하고, 가장 중요한 decision-making 역할에만 프리미엄 모델을 남겨두세요.
Specialized Workflows
Specialized Workflows
특정 도메인 전문성이 필요할 때: 주된 사용 사례에 최적화된 모델을 선택하세요. 코딩에는 Claude 4 시리즈, 리서치에는 Gemini 2.5 Pro, function calling에는 Llama 405B를 사용하세요.전략: crew의 주요 기능에 따라 모델을 선택해, 핵심 역량이 모델의 강점과 일치하도록 하세요.
Enterprise & Privacy
Enterprise & Privacy
데이터 민감한 operation의 경우: 로컬에서 배포 가능하면서 경쟁력 있는 퍼포먼스를 유지하는 오픈 소스 모델인 Llama 4 시리즈, DeepSeek V3, Qwen3 등을 고려하세요.전략: 사설 인프라에 오픈 소스 모델을 배포하여, 데이터 제어를 위해 필요한 퍼포먼스 손실을 감수하세요.
모델 선택을 위한 주요 고려사항
- 성능 동향: 현재 시장에서는 reasoning에 초점을 맞춘 모델(o3, Gemini 2.5 Pro)과 균형 잡힌 모델(Claude 4, GPT-4.1) 간의 치열한 경쟁이 있습니다. DeepSeek R1과 같은 특화 모델은 우수한 비용-성능 비율을 제공합니다.
- 속도와 지능 간의 트레이드오프: Llama 4 Scout와 같은 모델은 합리적인 지능을 유지하면서도 빠른 속도(2,600 tokens/s)를 우선시하며, o3와 같은 모델은 속도와 가격을 희생해 reasoning 능력을 극대화합니다.
- 오픈 소스의 실효성: 오픈 소스와 독점 모델 간의 격차가 계속 좁혀지고 있으며, Llama 4 Maverick 및 DeepSeek V3와 같은 모델이 매력적인 가격대에서 경쟁력 있는 성능을 제공합니다. 특히 빠른 추론을 제공하는 업체들은 오픈 소스 모델과 함께 탁월한 속도-비용 비율을 제공하는 경우가 많아 독점 모델보다 우위에 서기도 합니다.
테스트는 필수입니다: 리더보드 순위는 일반적인 가이드라인을 제공하지만,
귀하의 특정 사용 사례, 프롬프트 스타일, 평가 기준에 따라 결과가 달라질 수
있습니다. 최종 결정을 내리기 전에 반드시 실제 작업과 데이터로 후보 모델을
테스트해 보세요.
실질적인 구현 전략
검증된 모델로 시작하기
여러 차원에서 우수한 성능을 제공하며 실제 환경에서 광범위하게 검증된 GPT-4.1, Claude 3.7 Sonnet, Gemini 2.0 Flash와 같은 잘 알려진 모델부터 시작하십시오.
특화된 요구 사항 식별
crew에 코드 작성, reasoning, 속도 등 특정 요구가 있는지 확인하고, 이러한
요구에 부합하는 Claude 4 Sonnet(개발용) 또는 o3(복잡한 분석용)과 같은
특화 모델을 고려하십시오. 속도가 중요한 애플리케이션의 경우, 모델 선택과
더불어 Groq와 같은 빠른 추론 제공자를 고려할 수 있습니다.