Salve automaticamente o estado de execução para que crews, flows e agentes possam retomar após falhas.
O checkpointing salva um snapshot do estado de execução durante uma execução para que uma crew, flow ou agente possa retomar após uma falha ou ser bifurcado em uma branch alternativa.
Explicação
Como o checkpointing funciona: eventos, armazenamento e herança.
Tutorial
Um passo a passo de 5 minutos: executar, interromper, retomar.
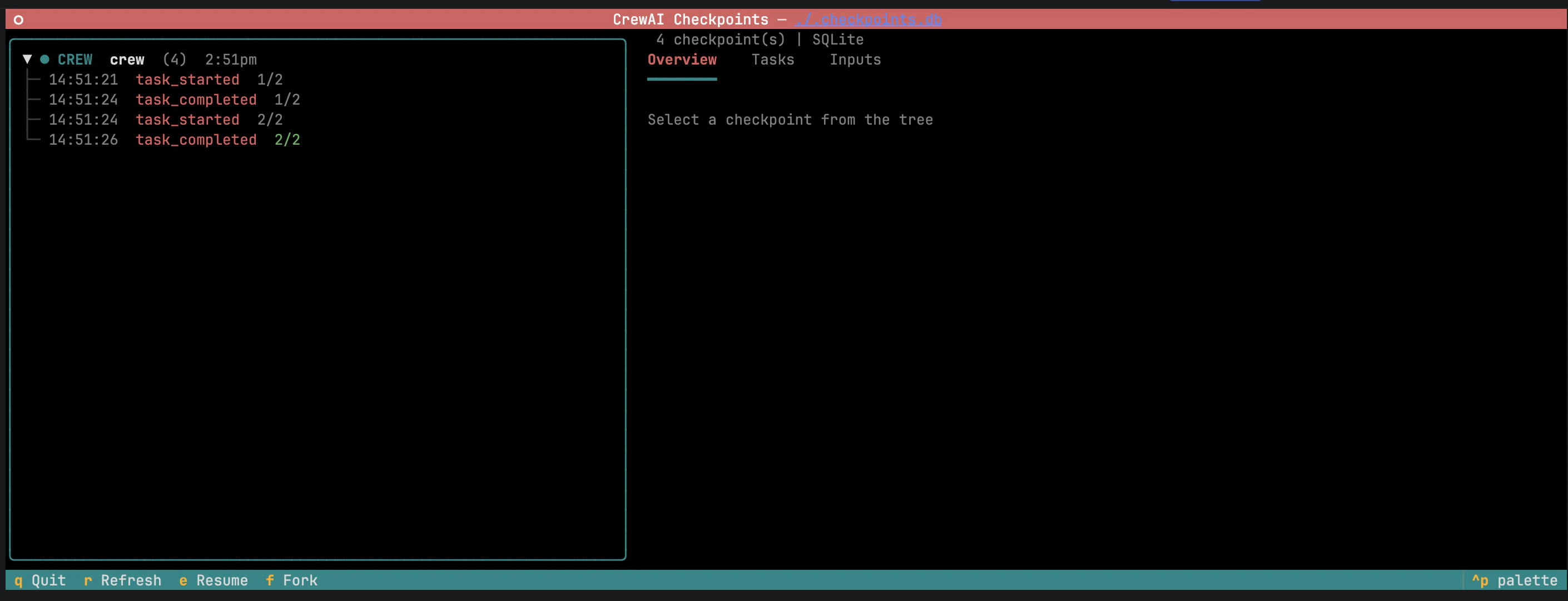
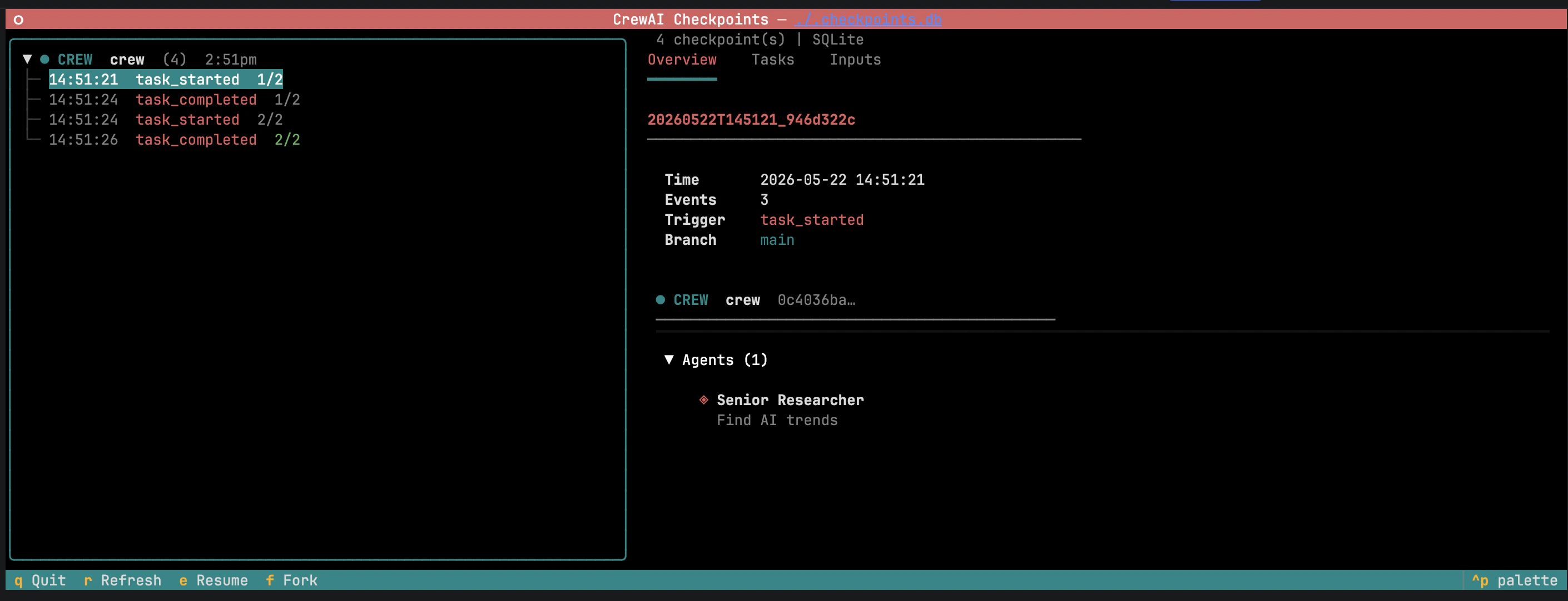
Um checkpoint captura tudo o que o CrewAI precisa para recriar uma execução em andamento: o estado completo da crew, flow ou agente — configuração, memória e fontes de conhecimento dos agentes, progresso das tarefas, saídas intermediárias, estado interno e atributos — junto com os inputs do kickoff, o histórico de eventos até aquele ponto e um ID de linhagem que liga o checkpoint à execução de origem.Restaurar reconstrói esse estado e continua. Tarefas concluídas são puladas, memória e conhecimento são reidratados, e o trabalho downstream roda contra as mesmas saídas que a execução original produziu. Fazer fork executa a mesma restauração sob uma nova linhagem, para que a nova branch e a execução original gravem checkpoints lado a lado sem sobrescrever uma a outra.
O checkpointing é orientado a eventos. O runtime se inscreve nos eventos selecionados em on_events e grava um checkpoint sempre que um é disparado. O padrão task_completed produz um checkpoint por tarefa finalizada — um equilíbrio razoável entre granularidade e uso de disco. Eventos de alta frequência como llm_call_completed estão disponíveis para recuperação mais granular, mas gravam muito mais arquivos.
JsonProvider grava um arquivo por checkpoint. Legível e fácil de inspecionar.
SqliteProvider grava em um único banco SQLite. Melhor para checkpointing de alta frequência.
Ambos removem os checkpoints mais antigos quando max_checkpoints está definido.
Gravações de checkpoint automáticas (acionadas por evento) são best-effort: uma falha é registrada em log e a execução continua. Chamadas manuais a state.checkpoint() e state.acheckpoint() relançam a exceção.
Crew, Flow e Agent aceitam um argumento checkpoint. Filhos herdam do pai a menos que definam seu próprio valor ou passem False para desativar. Ative o checkpointing uma vez na crew e todos os agentes participam, ou exclua um agente seletivamente.
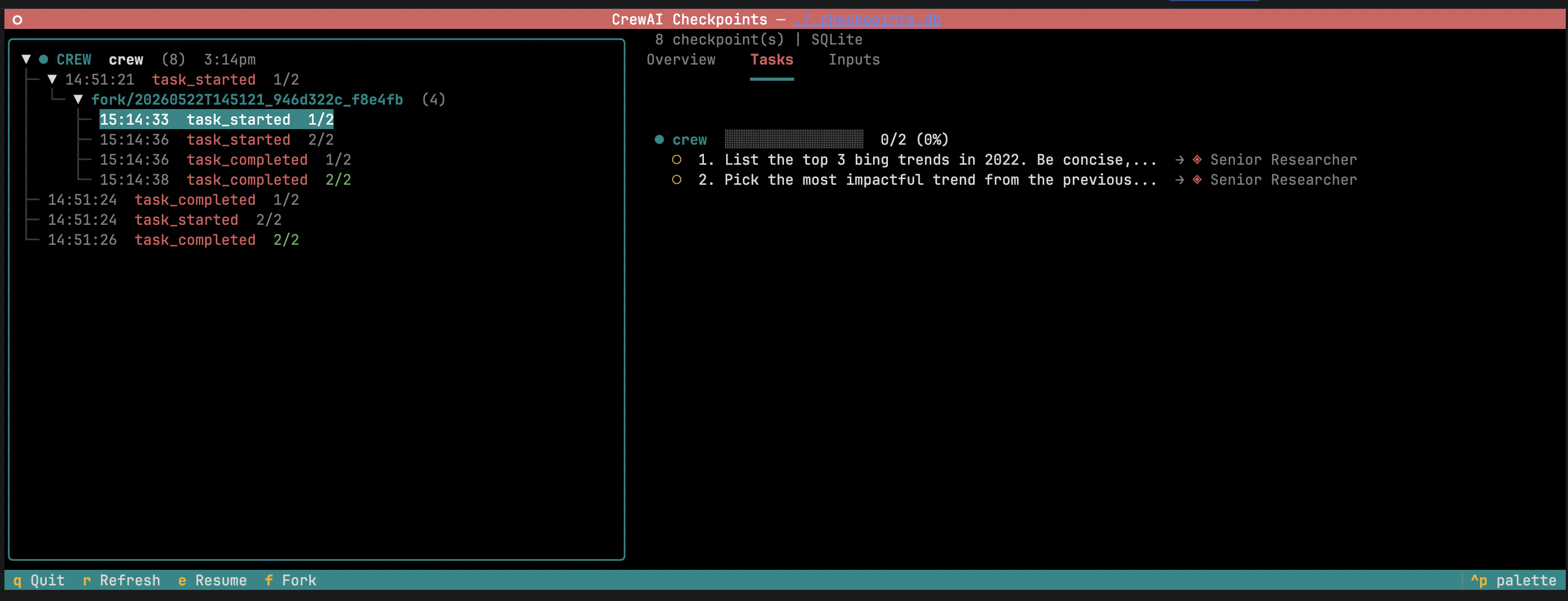
O painel esquerdo agrupa checkpoints por branch; forks aninham sob seu pai. Selecionar um checkpoint abre o painel de detalhes com metadados, estado da entidade e progresso das tarefas. Resume continua a execução; Fork inicia uma nova branch.
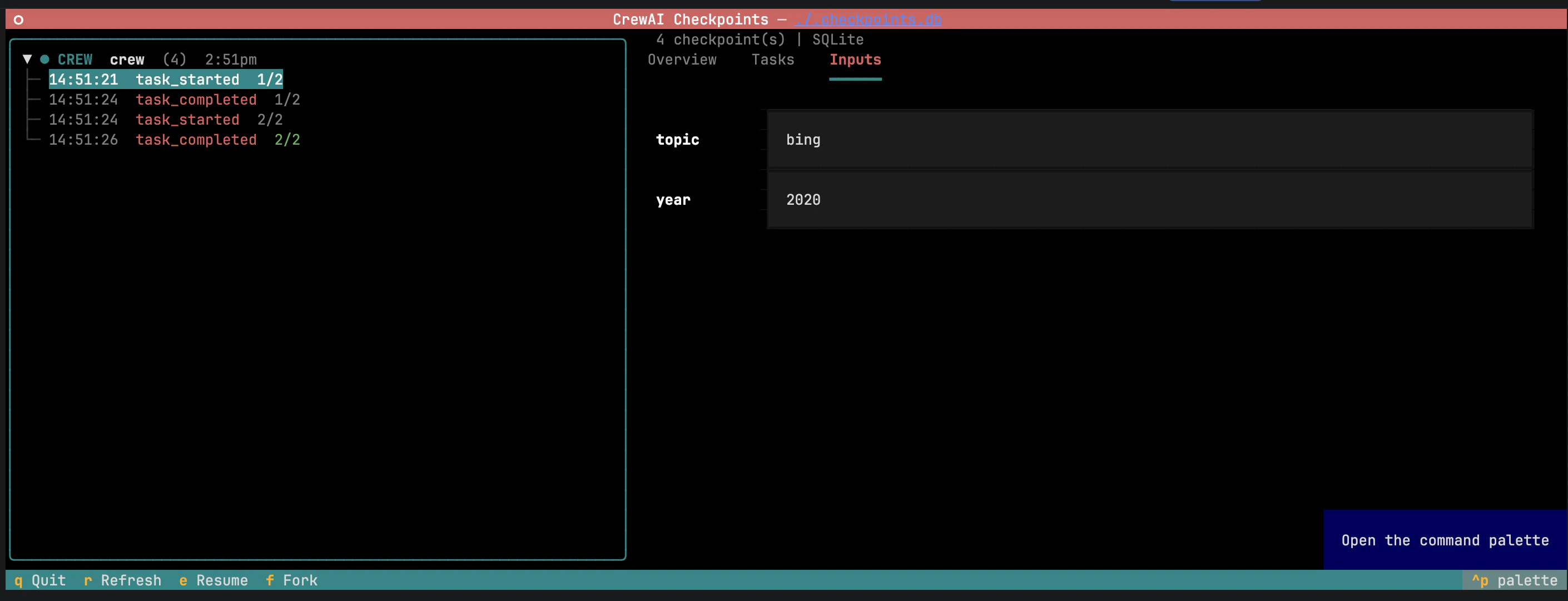
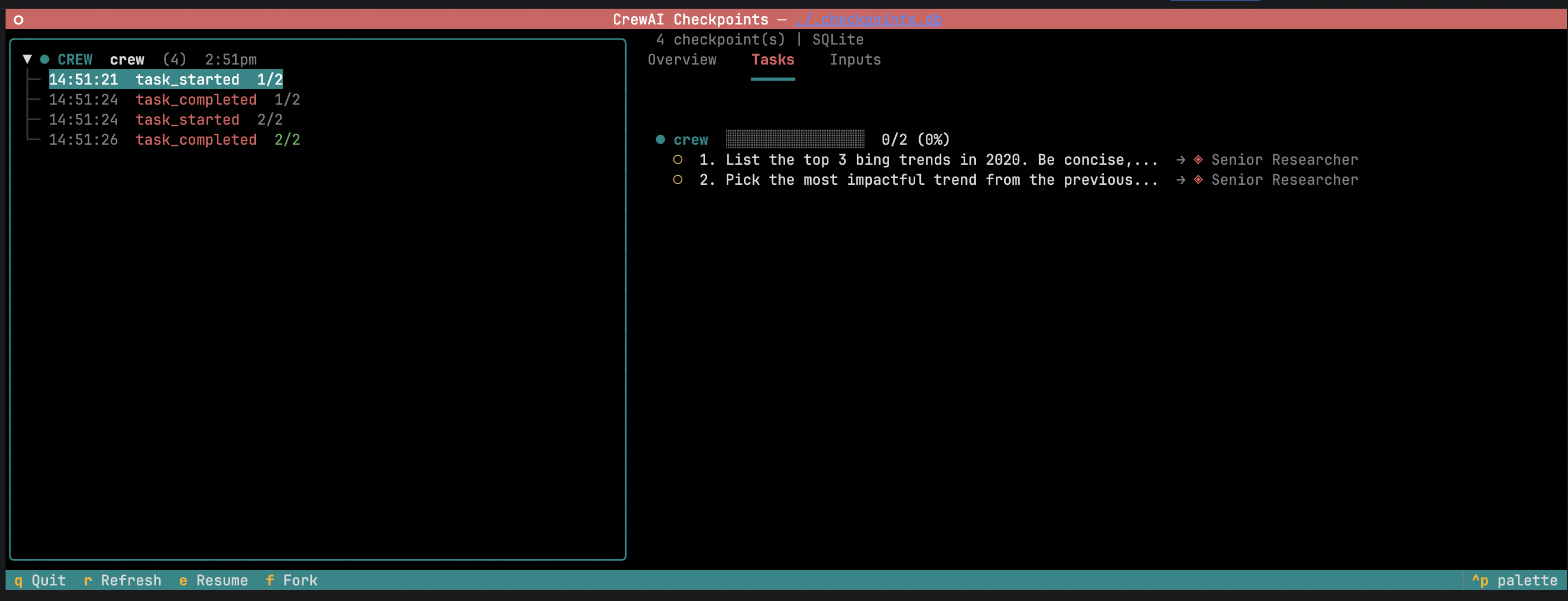
O painel de detalhes expõe duas áreas editáveis:
Inputs — os inputs originais do kickoff, preenchidos e editáveis.
Saídas das tarefas — saídas das tarefas concluídas. Editar uma saída e pressionar Fork invalida tarefas downstream para que sejam reexecutadas com o contexto modificado.
Útil para exploração de cenários: fork, ajuste, observe.
Inspecionar checkpoints sem a TUI
crewai checkpoint list ./my_checkpointscrewai checkpoint info ./my_checkpoints/<file>.jsoncrewai checkpoint info ./.checkpoints.db
Tipos de evento que disparam um checkpoint. CheckpointEventType é um Literal — seu type checker autocompleta e rejeita valores não suportados. Veja tipos de evento para a lista completa.
on_events aceita qualquer combinação de valores CheckpointEventType. O padrão ["task_completed"] grava um checkpoint por tarefa finalizada; ["*"] corresponde a todos os eventos.
["*"] e eventos de alta frequência como llm_call_completed gravam muitos checkpoints e podem degradar o desempenho. Combine com max_checkpoints.