Em vez de recomendações prescritivas de modelos, defendemos um framework de pensamento que ajude você a tomar decisões informadas com base no seu caso de uso, restrições e requisitos específicos. O cenário de LLMs evolui rapidamente, com novos modelos surgindo regularmente e os existentes sendo atualizados frequentemente. O que mais importa é desenvolver uma abordagem sistemática de avaliação que permaneça relevante independentemente dos modelos disponíveis no momento.
Este guia foca em pensamento estratégico em vez de recomendações de modelos
específicos, já que o cenário dos LLMs evolui rapidamente.
Comece entendendo profundamente o que suas tarefas realmente exigem.
Considere a complexidade cognitiva envolvida, a profundidade de raciocínio
necessária, o formato dos resultados esperados e a quantidade de contexto
que o modelo precisará processar. Essa análise fundamental guiará todas as
decisões seguintes.
2
Mapeie as Capacidades dos Modelos
Assim que você compreende seus requisitos, mapeie-os para as forças dos
modelos. Diferentes famílias de modelos se destacam em diferentes tipos de
trabalho; alguns são otimizados para raciocínio e análise, outros para
criatividade e geração de conteúdo, e outros para velocidade e eficiência.
3
Considere Restrições
Leve em conta suas reais restrições operacionais, incluindo limitações
orçamentárias, requisitos de latência, necessidades de privacidade de dados
e capacidades de infraestrutura. O melhor modelo teoricamente pode não ser a
melhor escolha prática para sua situação.
4
Teste e Itere
Comece com modelos confiáveis e bem conhecidos e otimize com base no
desempenho real no seu caso de uso. Os resultados práticos frequentemente
diferem dos benchmarks teóricos, então testes empíricos são cruciais.
O passo mais crítico na seleção de LLMs é entender o que sua tarefa realmente exige. Frequentemente, equipes escolhem modelos com base em reputação geral ou pontuações de benchmark, sem analisar cuidadosamente suas necessidades específicas. Essa abordagem leva tanto ao superdimensionamento de tarefas simples usando modelos caros e complexos quanto à subutilização em tarefas sofisticadas com modelos sem as capacidades necessárias.
Complexidade de Raciocínio
Requisitos de Saída
Necessidades de Contexto
Tarefas Simples representam a maioria do trabalho diário de IA e incluem seguir instruções básicas, processar dados simples e formatação elementar. Estas tarefas geralmente têm entradas e saídas claras, com mínima ambiguidade. A carga cognitiva é baixa e o modelo precisa apenas seguir instruções explícitas, não realizar raciocínio complexo.
Tarefas Complexas exigem raciocínio de múltiplas etapas, pensamento estratégico e a capacidade de lidar com informações ambíguas ou incompletas. Podem envolver análise de múltiplas fontes de dados, desenvolvimento de estratégias abrangentes ou resolução de problemas que precisam ser decompostos em componentes menores. O modelo deve manter o contexto ao longo de várias etapas de raciocínio e frequentemente precisa inferir informações não explicitamente declaradas.
Tarefas Criativas exigem um tipo diferente de capacidade cognitiva, focada em gerar conteúdo novo, envolvente e adequado ao contexto. Isso inclui storytelling, criação de textos de marketing e solução criativa de problemas. O modelo deve compreender nuances, tom e público, produzindo conteúdo autêntico e envolvente, não apenas fórmulas.
Dados Estruturados exigem precisão e consistência na adesão ao formato. Ao trabalhar com JSON, XML ou formatos de banco de dados, o modelo deve produzir saídas sintaticamente corretas, que possam ser processadas programaticamente. Essas tarefas possuem requisitos rígidos de validação e pouca tolerância a erros de formato, tornando a confiabilidade mais importante que a criatividade.
Conteúdo Criativo requer equilíbrio entre competência técnica e criatividade. O modelo precisa compreender o público, tom e voz da marca, ao mesmo tempo em que produz conteúdo que engaja leitores e atinge objetivos comunicativos específicos. A qualidade aqui é mais subjetiva e exige modelos capazes de adaptar o estilo de escrita a diferentes contextos e propósitos.
Conteúdo Técnico situa-se entre dados estruturados e conteúdo criativo, demandando precisão e clareza. Documentação, geração de código e análises técnicas precisam ser exatas e completas, mas ainda assim acessíveis ao público-alvo. O modelo deve entender conceitos técnicos complexos e comunicá-los de forma eficaz.
Contexto Curto envolve tarefas imediatas e focalizadas, onde o modelo processa informações limitadas rapidamente. São interações transacionais em que velocidade e eficiência importam mais do que compreensão profunda. O modelo não precisa manter histórico extenso ou processar grandes documentos.
Contexto Longo é necessário ao lidar com documentos substanciais, conversas extensas ou tarefas complexas de múltiplas partes. O modelo precisa manter coerência ao longo de milhares de tokens, referenciando informações anteriores com precisão. Essencial para análise de documentos, pesquisa abrangente e sistemas de diálogo sofisticados.
Contexto Muito Longo ultrapassa os limites do possível hoje, com processamento de documentos massivos, síntese de pesquisas extensas ou interações multi-sessão. São casos que exigem modelos projetados especificamente para lidar com contexto estendido e envolvem trade-offs entre extensão e velocidade.
Entender as capacidades dos modelos exige ir além do marketing e dos benchmarks, analisando forças e limitações fundamentais das arquiteturas e métodos de treinamento.
Modelos de Raciocínio
Modelos de raciocínio formam uma categoria especializada, projetada para tarefas de pensamento complexo e de múltiplas etapas. Eles se destacam na resolução de problemas que requerem análise cuidadosa, planejamento estratégico ou decomposição sistemática. Normalmente aplicam técnicas como chain-of-thought ou tree-of-thought para conduzir o raciocínio passo a passo.O ponto forte é manter consistência lógica em cadeias longas de raciocínio e decompor problemas complexos em partes gerenciáveis. São especialmente valiosos para planejamento estratégico, análise complexa e situações onde a qualidade do raciocínio importa mais que a velocidade.Entretanto, há trade-offs em termos de custo e velocidade. Podem ser menos adequados para tarefas criativas ou operações simples, onde suas capacidades avançadas não são necessárias. Considere-os quando as tarefas realmente se beneficiarem dessa análise detalhada.
Modelos de Uso Geral
Modelos de uso geral oferecem uma abordagem equilibrada, com desempenho sólido em uma ampla gama de tarefas, sem especialização extrema. São treinados em conjuntos de dados diversificados e otimizados para versatilidade.A principal vantagem é a confiabilidade previsível em diversos trabalhos: pesquisa, análise, criação de conteúdo, processamento de dados. São ótimas opções iniciais para equipes que buscam consistência ao lidar com fluxos variados.Embora não atinjam picos de desempenho como modelos especializados, oferecem simplicidade operacional e baixa complexidade na gestão. São o melhor ponto de partida para novos projetos, permitindo descobertas de necessidades antes de avançar para otimizações.
Modelos Rápidos & Eficientes
Modelos rápidos e eficientes priorizam velocidade, custo e eficiência de recursos, em vez de raciocínio sofisticado. São otimizados para cenários de alto volume onde respostas rápidas e baixos custos são mais importantes que compreensão ou criatividade profunda.Brilham em operações rotineiras, processamento simples de dados, chamadas de funções e tarefas de alto volume. Aplicações que processam muitos pedidos rapidamente ou operam sob restrições orçamentárias se beneficiam desses modelos.O ponto crucial é garantir que suas capacidades atendam às exigências da tarefa. Podem não atender tarefas que exijam entendimento profundo, raciocínio complexo ou geração de conteúdo sofisticado. São ideais para tarefas rotineiras bem definidas.
Modelos Criativos
Modelos criativos são otimizados para geração de conteúdo, qualidade de escrita e pensamento inovador. Excelentes na compreensão de nuances, tom e estilo, produzindo conteúdo envolvente e natural.O ponto forte está em adaptar o estilo para diferentes públicos, manter voz e tom consistentes e engajar leitores. Performam melhor em storytelling, textos publicitários, comunicações de marca e outras tarefas com criatividade como foco.Ao selecionar esses modelos, considere não apenas a habilidade de gerar texto, mas a compreensão de público, contexto e objetivo. Os melhores modelos criativos adaptam a saída à voz da marca, diferentes segmentos e mantêm consistência em peças longas.
Modelos Open Source
Modelos open source oferecem vantagens em controle de custos, potencial de customização, privacidade de dados e flexibilidade de deployment. Podem ser rodados localmente ou em infraestrutura própria, dando controle total sobre dados e comportamento.Os principais benefícios incluem eliminação de custos por token, possibilidade de fine-tuning, privacidade total e independência de fornecedores externos. Perfeitos para organizações com necessidade de privacidade, orçamento limitado ou desejo de customização.Contudo, requerem maior expertise técnica para implantar e manter. Considere custos de infraestrutura, complexidade de gestão e esforços contínuos de atualização e otimização ao avaliar modelos open source. O custo total pode ser maior que o de alternativas em nuvem devido a esse overhead.
Use diferentes modelos para diferentes propósitos dentro da mesma crew para
otimizar desempenho e custos.
As implementações CrewAI mais sofisticadas empregam múltiplos modelos estrategicamente, designando-os conforme as funções e necessidades dos agentes. Assim, é possível otimizar desempenho e custos usando o modelo mais adequado para cada tipo de tarefa.Agentes de planejamento se beneficiam de modelos de raciocínio para pensamento estratégico e análise multi-etapas. Esses agentes funcionam como o “cérebro” da operação. Agentes de conteúdo têm melhor desempenho com modelos criativos focados em qualidade de escrita e engajamento. Agentes de processamento, responsáveis por operações rotineiras, podem usar modelos eficientes priorizando velocidade.Exemplo: Crew de Pesquisa e Análise
from crewai import Agent, Task, Crew, LLM# Modelo de raciocínio para planejamento estratégicomanager_llm = LLM(model="gemini-2.5-flash-preview-05-20", temperature=0.1)# Modelo criativo para gerar conteúdocontent_llm = LLM(model="claude-3-5-sonnet-20241022", temperature=0.7)# Modelo eficiente para processamento de dadosprocessing_llm = LLM(model="gpt-4o-mini", temperature=0)research_manager = Agent( role="Research Strategy Manager", goal="Develop comprehensive research strategies and coordinate team efforts", backstory="Expert research strategist with deep analytical capabilities", llm=manager_llm, # Modelo de alto nível para raciocínio complexo verbose=True)content_writer = Agent( role="Research Content Writer", goal="Transform research findings into compelling, well-structured reports", backstory="Skilled writer who excels at making complex topics accessible", llm=content_llm, # Modelo criativo para conteúdo envolvente verbose=True)data_processor = Agent( role="Data Analysis Specialist", goal="Extract and organize key data points from research sources", backstory="Detail-oriented analyst focused on accuracy and efficiency", llm=processing_llm, # Modelo rápido para tarefas rotineiras verbose=True)crew = Crew( agents=[research_manager, content_writer, data_processor], tasks=[...], # Suas tarefas específicas manager_llm=manager_llm, # Manager usa o modelo de raciocínio verbose=True)
O segredo do sucesso na implementação multi-modelo está em entender como os agentes interagem e garantir que as capacidades dos modelos estejam alinhadas às responsabilidades. Isso exige planejamento estratégico, mas traz ganhos significativos em qualidade dos resultados e eficiência operacional.
O manager LLM desempenha papel central em fluxos hierárquicos CrewAI, coordenando agentes e tarefas. Este modelo precisa se destacar em delegação, priorização de tarefas e manutenção de contexto em várias operações simultâneas.LLMs de manager eficazes exigem forte raciocínio para delegar bem, desempenho consistente para coordenar previsivelmente e excelente gestão de contexto para acompanhar o estado dos agentes. O modelo deve entender capacidades e limitações dos agentes enquanto otimiza a alocação de tarefas.O custo é especialmente relevante, já que este LLM participa de todas as operações. O modelo precisa entregar capacidades suficientes, sem o preço premium de opções sofisticadas demais, buscando sempre o equilíbrio entre performance e valor.
LLMs de function calling gerenciam o uso de ferramentas por todos os agentes, sendo críticos em crews que dependem fortemente de APIs externas e ferramentas. Devem ser precisos na extração de parâmetros e no processamento das respostas.As características mais importantes são precisão e confiabilidade, não criatividade ou raciocínio avançado. O modelo deve extrair parâmetros corretos de comandos em linguagem natural consistentemente e processar respostas de ferramentas adequadamente. Velocidade também importa, pois o uso de ferramentas pode envolver múltiplas idas e vindas de informação.Muitas equipes descobrem que modelos especializados em function calling ou de uso geral com forte suporte a ferramentas funcionam melhor do que modelos criativos ou de raciocínio nesse papel. O fundamental é assegurar que o modelo consiga converter instruções em chamadas estruturadas sem falhas.
Agentes individuais podem sobrescrever o LLM do nível da crew quando suas necessidades diferem significativamente das do restante. Isso permite otimização pontual, mantendo a simplicidade operacional para os demais agentes.Considere sobrescritas quando a função do agente exige capacidades distintas. Por exemplo, um agente de redação criativa pode se beneficiar de um LLM otimizado para geração de conteúdo, enquanto um analista de dados pode preferir um modelo voltado ao raciocínio.O desafio é balancear otimização com complexidade operacional. Cada modelo adicional aumenta a complexidade de deployment, monitoramento e custos. Foque em sobrescritas apenas quando a melhoria justificar essa complexidade.
Definir bem as tarefas é frequentemente mais importante do que a seleção do modelo no resultado gerado pelos agentes CrewAI. Tarefas bem formuladas orientam claramente mesmo modelos simples a terem bom desempenho. Já tarefas mal definidas prejudicam até os modelos mais avançados.
Descrições de Tarefas Eficazes
As melhores descrições de tarefas equilibram detalhamento e clareza. Devem definir o objetivo de forma clara e sem ambiguidade, além de explicar o método a ser usado com detalhes que permitam ao agente agir corretamente.Descrições eficazes incluem contexto relevante e restrições, ajudando o agente a entender o propósito maior e quaisquer limitações. Divida trabalhos complexos em etapas gerenciáveis em vez de objetivos genéricos e sobrecarregados.Erros comuns incluem objetivos vagos, falta de contexto, critérios de sucesso mal definidos ou mistura de tarefas totalmente distintas em um mesmo texto. O objetivo é passar informação suficiente para o sucesso, mas mantendo foco no resultado claro.
Diretrizes para a Saída Esperada
As diretrizes da saída esperada funcionam como contrato entre definição de tarefa e agente, especificando claramente o que deve ser entregue e como será avaliado. Elas abrangem formato, estrutura e elementos essenciais.As melhores diretrizes incluem exemplos concretos de indicadores de qualidade e critérios claros de conclusão, de modo que agente e revisores humanos possam avaliar o resultado facilmente. Isso reduz ambiguidades e garante resultados consistentes.Evite descrições genéricas que serviriam para qualquer tarefa, ausência de especificações de formato, padrões vagos ou falta de exemplos/modelos que ajudem o agente a entender as expectativas.
Dependências são essenciais quando as tarefas se baseiam em resultados prévios, informações fluem de uma tarefa para outra, ou a qualidade depende da conclusão de fases anteriores. Assim, cada tarefa recebe o contexto correto para o sucesso.Para implementar bem, use o parâmetro de contexto para encadear tarefas, desenvolvendo gradualmente a complexidade. Cada tarefa deve gerar saídas que alimentam as próximas. O objetivo é manter um fluxo lógico entre as tarefas dependentes, evitando gargalos desnecessários.Funciona melhor quando há progressão lógica evidente e quando a saída de uma tarefa realmente agrega valor nas etapas seguintes. Cuidado com os gargalos; foque nas dependências essenciais.
A execução paralela é valiosa quando as tarefas são independentes, o tempo é crítico ou há expertise distintas que não exigem coordenação. Pode reduzir drasticamente o tempo total, permitindo que agentes especializados atuem simultaneamente.Para isso, identifique tarefas realmente independentes, agrupe fluxos de trabalho distintos e planeje a integração dos resultados posteriormente. O ponto-chave é garantir que tarefas paralelas não gerem conflitos ou redundâncias.Considere o paralelo em múltiplos fluxos independentes, diferentes tipos de análise autônoma, ou criação de conteúdo que pode ser feita ao mesmo tempo. Mas atente-se à alocação de recursos, evitando sobrecarga de modelos ou estouro no orçamento.
Funções genéricas de agentes tornam impossível escolher o LLM certo. Funções
específicas permitem otimização do modelo conforme a função.
A especificidade das funções dos agentes determina quais capacidades de LLM mais importam para alto desempenho, criando oportunidade estratégica de alinhar forças do modelo ao papel do agente.Impacto de Funções Genéricas vs. Específicas:Ao definir funções, pense no conhecimento do domínio, estilo de trabalho e frameworks decisórios mais valiosos para o tipo de tarefa do agente. Quanto mais específica e contextualizada a função, melhor o modelo incorporará esse papel.
# ✅ Função específica - requisitos claros de LLMspecific_agent = Agent( role="SaaS Revenue Operations Analyst", # Expertise de domínio clara goal="Analyze recurring revenue metrics and identify growth opportunities", backstory="Specialist in SaaS business models with deep understanding of ARR, churn, and expansion revenue", llm=LLM(model="gpt-4o") # Raciocínio justificado para análise complexa)
Estratégia de Mapeamento de Função para Modelo:
“Research Analyst” → Modelo de raciocínio (GPT-4o, Claude Sonnet) para análise complexa
“Content Editor” → Modelo criativo (Claude, GPT-4o) para qualidade de escrita
b. Backstory como Amplificador de Contexto do Modelo
Backstories estratégicos maximizam a eficácia do LLM ao contextualizar as
respostas de forma que prompts genéricos não conseguem.
Um bom backstory transforma a escolha do LLM de genérica a especializada. Isso é crucial para otimizar custos: um modelo eficiente com contexto certo pode superar um premium sem contexto.Exemplo de Performance Guiada por Contexto:
# Contexto amplifica a efetividade do modelodomain_expert = Agent( role="B2B SaaS Marketing Strategist", goal="Develop comprehensive go-to-market strategies for enterprise software", backstory=""" You have 10+ years of experience scaling B2B SaaS companies from Series A to IPO. You understand the nuances of enterprise sales cycles, the importance of product-market fit in different verticals, and how to balance growth metrics with unit economics. You've worked with companies like Salesforce, HubSpot, and emerging unicorns, giving you perspective on both established and disruptive go-to-market strategies. """, llm=LLM(model="claude-3-5-sonnet", temperature=0.3) # Criatividade balanceada com conhecimento de domínio)# Esse contexto faz o Claude agir como especialista do setor# Sem isso, mesmo ele entregaria respostas genéricas
Elementos de Backstory que Potencializam a Performance de LLMs:
Experiência de Domínio: “10+ anos em vendas enterprise SaaS”
Expertise Específica: “Especialista em due diligence técnica para Série B+”
Estilo de Trabalho: “Decisões orientadas a dados, documentação clara”
Padrões de Qualidade: “Sempre cita fontes e mostra análise detalhada”
As configurações mais eficazes criam sinergia entre função específica, profundidade do backstory e escolha do LLM. Cada elemento reforça o outro para maximizar rendimento.Framework de Otimização:
# Exemplo: Agente de Documentação Técnicatech_writer = Agent( role="API Documentation Specialist", goal="Create comprehensive, developer-friendly API documentation", backstory=""" You're a technical writer with 8+ years documenting REST APIs, GraphQL endpoints, and SDK integration guides. You've worked with developer tools companies and understand what developers need: clear examples, comprehensive error handling, and practical use cases. You prioritize accuracy and usability over marketing fluff. """, llm=LLM( model="claude-3-5-sonnet", temperature=0.1 ), tools=[code_analyzer_tool, api_scanner_tool], verbose=True)
Checklist de Alinhamento:
✅ Função Específica: Domínio e responsabilidades claras
✅ Correspondência do LLM: Forças do modelo conectadas à função
✅ Profundidade do Backstory: Contexto de domínio disponível pro modelo
✅ Integração de Ferramentas: Ferramentas fortalecem a função do agente
✅ Ajuste de Parâmetros: Temperatura e configs otimizadas para a função
O segredo é criar agentes onde cada configuração reforça sua estratégia de escolha do LLM, maximizando rendimento e otimizando custos.
Em vez de repetir o framework estratégico, segue um checklist tático para implementar as decisões de seleção de LLM em CrewAI:
Audite Sua Configuração Atual
O que analisar:
Todos os agentes usam o mesmo LLM por padrão?
Quais agentes lidam com tarefas mais complexas?
Quais agentes só processam ou formatam dados?
Algum agente depende fortemente de ferramentas?
Ação: Documente funções dos agentes e identifique oportunidades de otimização.
Implemente Estratégia no Nível da Crew
Defina sua Base:
# Comece com um padrão confiável para a crewdefault_crew_llm = LLM(model="gpt-4o-mini") # Base econômicacrew = Crew( agents=[...], tasks=[...], memory=True)
Ação: Defina o LLM padrão da crew antes de otimizar agentes individuais.
Otimize Agentes de Maior Impacto
Identifique e Aprimore Agentes-Chave:
# Agentes gerenciadores ou de coordenaçãomanager_agent = Agent( role="Project Manager", llm=LLM(model="gemini-2.5-flash-preview-05-20"), # ... demais configs)# Agentes criativos ou customer-facingcontent_agent = Agent( role="Content Creator", llm=LLM(model="claude-3-5-sonnet"), # ... demais configs)
Ação: Faça upgrade dos 20% dos agentes que tratam 80% da complexidade.
Modelos de raciocínio tornam-se essenciais quando tarefas exigem pensamento lógico genuíno em múltiplas etapas, planejamento estratégico ou decisões complexas beneficiadas por análise sistemática. Brilham na decomposição de problemas e análise estruturada, não no simples seguimento de padrões.Considere-os para desenvolvimento de estratégias de negócios, análise de dados combinados de múltiplas fontes, resolução de problemas dependente de etapas sucessivas e planejamento estratégico envolvendo múltiplas variáveis.Entretanto, esses modelos são mais caros e lentos, devendo ser reservados para tarefas onde suas capacidades agregam valor real — evite usá-los apenas para operações simples.
Modelos criativos são valiosos quando a principal entrega é geração de conteúdo e a qualidade, estilo e engajamento desse conteúdo impactam o sucesso. Se destacam quando redação e estilo importam, ideação criativa é necessária, ou voz de marca é fundamental.Use-os em redação de posts, criação de artigos, textos de marketing com viés persuasivo, storytelling e comunicações da marca. Costumam captar nuances e contexto melhor do que generalistas.Podem ser menos adequados para tarefas técnicas ou analíticas, onde precisão supera criatividade. Use-os quando aspectos comunicativos são fatores críticos de sucesso.
Modelos eficientes são ideais para operações frequentes e rotineiras, onde velocidade e custo são prioridade. Trabalham melhor em tarefas com parâmetros bem definidos, sem necessidade de raciocínio avançado ou criatividade.Considere-os para processamento e transformação de dados, formatação simples, chamadas de funções (function calling) e operações em alto volume onde custo importa mais.O ponto crítico é verificar adequação à tarefa. Funcionam para muitos fluxos rotineiros, mas podem falhar se a tarefa exigir compreensão técnica ou raciocínio.
Modelos open source são atraentes quando há restrição orçamentária, necessidade de privacidade, personalização especial ou exigência de deployment local.Considere para ferramentas internas de empresas, aplicações sensíveis, projetos onde não é possível usar APIs externas, casos com orçamento apertado ou requisitos de customização.Mas lembre-se: exigem mais expertise, manutenção e investimentos em infraestrutura. Avalie o custo total da operação ao avaliar esses modelos.
O problema: Usar o mesmo LLM para todos os agentes, independentemente das funções. Prática padrão, mas raramente ótima.Exemplo real: Usar GPT-4o tanto para planejamento estratégico quanto para extração simples de dados. O manager precisa do raciocínio premium, mas o extrator poderia usar o GPT-4o-mini, muito mais barato.Solução CrewAI: Configure modelos específicos por agente:
O problema: Não entender como funciona a hierarquia LLM da CrewAI — configurações conflitam entre crew, manager e agentes.Exemplo real: Configurar crew com Claude, mas agentes com GPT, gerando comportamento inconsistente e trocas desnecessárias.Solução CrewAI: Planeje a hierarquia estrategicamente:
crew = Crew( agents=[agent1, agent2], tasks=[task1, task2], manager_llm=LLM(model="gpt-4o"), process=Process.hierarchical)# Agentes herdam o LLM da crew, salvo sobrescritaagent1 = Agent(llm=LLM(model="claude-3-5-sonnet"))
Incompatibilidade para Function Calling
O problema: Escolher modelos pela capacidade geral e ignorar o desempenho em function calling em workflows intensivos em ferramentas.Exemplo real: Selecionar modelo criativo para agente que só precisa chamar APIs e processar dados estruturados, resultando em má extração de parâmetros.Solução CrewAI: Priorize desempenho em function calling para agentes que usam ferramentas:
# Para agentes com muitas ferramentastool_agent = Agent( role="API Integration Specialist", tools=[search_tool, api_tool, data_tool], llm=LLM(model="gpt-4o"), # OU llm=LLM(model="claude-3-5-sonnet"))
Otimização Prematura sem Teste
O problema: Decidir configurações complexas de modelo com base em hipóteses não validadas nos fluxos e tarefas reais CrewAI.Exemplo real: Implementar lógica elaborada de troca de modelo por tipo de tarefa sem testar se os ganhos compensam a complexidade.Solução CrewAI: Comece simples e otimize baseado em dados reais:
# Comece assimcrew = Crew(agents=[...], tasks=[...], llm=LLM(model="gpt-4o-mini"))# Teste a performance e só depois otimize agentes específicos# Use testes Enterprise para validar melhorias
Ignorar Limites de Contexto e Memória
O problema: Não considerar como janela de contexto dos modelos interage com memória e compartilhamento de contexto entre agentes CrewAI.Exemplo real: Usar modelo de contexto curto para agentes que precisam manter histórico ao longo de múltiplas iterações ou equipes com comunicação extensiva agent-to-agent.Solução CrewAI: Alinhe capacidades de contexto ao padrão de comunicação da crew.
Comece com modelos de uso geral, confiáveis e amplamente suportados. Isso
estabelece base estável para entender necessidades e expectativas de
desempenho antes de otimizar para demandas especializadas.
Meça o que Importa
Desenvolva métricas alinhadas ao seu caso de uso e metas de negócio, não
apenas benchmarks gerais. Foque na mensuração de resultados relevantes ao
seu sucesso.
Itere Baseado em Resultados
Faça mudanças baseadas no desempenho observado no seu contexto, não apenas
considerações teóricas ou recomendações genéricas. O desempenho prático
costuma ser bem diferente dos benchmarks.
Considere o Custo Total
Avalie todo custo de operação, incluindo modelo, tempo de desenvolvimento,
manutenção e complexidade. O modelo mais barato por token pode não ser o
mais econômico ao considerar todos os fatores.
Foque em entender seus requisitos primeiro, e então escolha modelos que melhor
correspondam a essas necessidades. O melhor LLM é aquele que consistentemente
entrega os resultados esperados dentro das suas restrições.
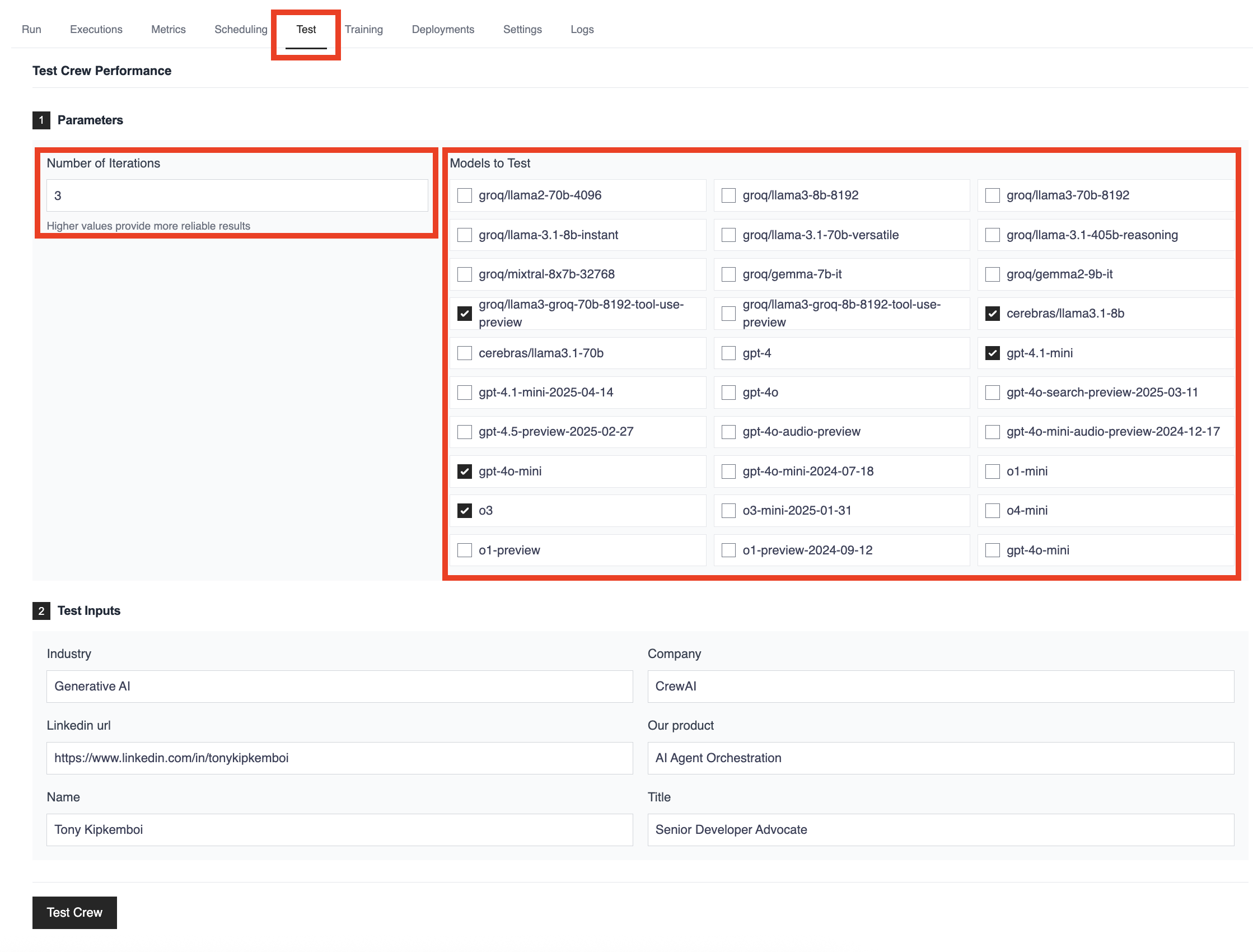
Para equipes sérias sobre otimização, a plataforma CrewAI AMP oferece testes sofisticados que vão além do CLI. Ela permite avaliação completa para decisões orientadas por dados na estratégia de LLM.
Funcionalidades Avançadas de Teste:
Comparação Multi-Modelo: Teste diversos LLMs simultaneamente nas mesmas tarefas e entradas. Compare desempenho entre GPT-4o, Claude, Llama, Groq, Cerebras, e outros líderes em paralelo para identificar a melhor opção para você.
Rigor Estatístico: Configure múltiplas iterações com inputs consistentes para medir confiabilidade e variação no desempenho. Assim, identifica modelos que performam bem e de modo consistente.
Validação no Mundo Real: Use os inputs e cenários reais da sua crew, e não apenas benchmarks sintéticos. A plataforma permite testar no contexto da sua indústria, empresa e casos de uso.
Analytics Completo: Acesse métricas detalhadas de desempenho, tempos de execução e análise de custos para todos os modelos testados. Decisões baseadas em dados reais, não apenas reputação.
Colaboração em Equipe: Compartilhe resultados e análises com seu time, favorecendo decisões coletivas e estratégias alinhadas.
A plataforma Enterprise transforma a seleção de modelos de um “palpite” para
um processo orientado por dados, permitindo validar os princípios deste guia
com seus próprios casos de uso.
Escolha os modelos pelo que sua tarefa realmente requer, não por reputação ou capacidades teóricas.
Combinação de Capacidades
Alinhe forças do modelo a papéis e responsabilidades dos agentes para melhor
desempenho.
Consistência Estratégica
Mantenha uma estratégia coerente de seleção de modelos em fluxos e componentes
relacionados.
Testes Práticos
Valide escolhas em uso real, não apenas em benchmarks.
Iteração Contínua
Comece simples e otimize com base na performance e necessidade práticas.
Equilíbrio Operacional
Equilibre performance requerida, custo e complexidade.
Lembre-se: o melhor LLM é o que entrega consistentemente os resultados de que
você precisa dentro de suas restrições. Conheça seu requisito primeiro, depois
selecione o modelo mais adequado.
Retrato do Momento: Os rankings a seguir representam o estado da arte em
Junho de 2025, compilados do LMSys Arena,
Artificial Analysis e outros benchmarks
líderes. Performance, disponibilidade e preço mudam rapidamente. Sempre valide
com seus dados e casos reais.
As tabelas abaixo mostram uma amostra dos modelos de maior destaque em cada categoria, junto de orientação sobre aplicação em agentes CrewAI:
Estas tabelas exibem apenas alguns modelos líderes por categoria. Existem
muitos outros excelentes. O objetivo é ilustrar exemplos de capacidades
buscadas em vez de apresentar um catálogo completo.
Raciocínio & Planejamento
Codificação & Técnica
Velocidade & Eficiência
Performance Equilibrada
Melhores para LLMs Manager e Análises Complexas
Modelo
Score de Inteligência
Custo ($/M tokens)
Velocidade
Melhor Uso em CrewAI
o3
70
$17.50
Rápido
Manager LLM para coordenação multi-agente
Gemini 2.5 Pro
69
$3.44
Rápido
Agentes de planejamento estratégico, coordenação de pesquisa
DeepSeek R1
68
$0.96
Moderada
Raciocínio com bom custo-benefício
Claude 4 Sonnet
53
$6.00
Rápido
Agentes de análise que precisam de nuance
Qwen3 235B (Reasoning)
62
$2.63
Moderada
Alternativa open source para raciocínio
Esses modelos se destacam em raciocínio multi-etapas e são ideais para agentes que desenvolvem estratégias, coordenam outros agentes ou analisam informações complexas.
Melhores para Desenvolvimento e Workflows com Ferramentas
Modelo
Performance em Coding
Tool Use Score
Custo ($/M tokens)
Melhor Uso em CrewAI
Claude 4 Sonnet
Excelente
72.7%
$6.00
Agente principal de código/documentação técnica
Claude 4 Opus
Excelente
72.5%
$30.00
Arquitetura complexa, code review
DeepSeek V3
Muito bom
Alto
$0.48
Coding econômico para desenvolvimentos rotineiros
Qwen2.5 Coder 32B
Muito bom
Médio
$0.15
Agente de código econômico
Llama 3.1 405B
Bom
81.1%
$3.50
LLM para function calling em workflows intensivos em ferramentas
Otimizados para geração de código, debugging e solução técnica, ideais para equipes de desenvolvimento.
Melhores para Operações em Massa e Aplicações em Tempo Real
Modelo
Velocidade (tokens/s)
Latência (TTFT)
Custo ($/M tokens)
Melhor Uso em CrewAI
Llama 4 Scout
2.600
0.33s
$0.27
Agentes de processamento de alto volume
Gemini 2.5 Flash
376
0.30s
$0.26
Agentes de resposta em tempo real
DeepSeek R1 Distill
383
Variável
$0.04
Processamento rápido de baixo custo
Llama 3.3 70B
2.500
0.52s
$0.60
Equilíbrio entre velocidade e capacidade
Nova Micro
Alto
0.30s
$0.04
Execução rápida de tarefas simples
Priorizam velocidade e eficiência, perfeitos para agentes em operações de rotina ou resposta ágil. Dica: Usar provedores de inference rápidos como Groq potencializa open source como Llama.
Melhores Modelos Coringa para Crews Diversos
Modelo
Score Global
Versatilidade
Custo ($/M tokens)
Melhor Uso em CrewAI
GPT-4.1
53
Excelente
$3.50
LLM generalista para equipes variadas
Claude 3.7 Sonnet
48
Muito boa
$6.00
Raciocínio e criatividade balanceados
Gemini 2.0 Flash
48
Boa
$0.17
Generalista de bom custo benefício
Llama 4 Maverick
51
Boa
$0.37
Open source para usos gerais
Qwen3 32B
44
Boa
$1.23
Versatilidade econômica
Oferecem bom desempenho geral, adequados para crews com demandas amplas.
Priorizando performance: Use modelos topo de linha como o3, Gemini 2.5 Pro ou Claude 4 Sonnet para managers e agentes críticos. Excelentes em raciocínio e coordenação, porém mais caros.Estratégia: Implemente abordagem multi-modelo, reservando premium para raciocínio estratégico e eficientes para operações rotineiras.
Crews de Baixo Custo
Foco no orçamento: Foque em modelos como DeepSeek R1, Llama 4 Scout ou Gemini 2.0 Flash, que trazem ótimo desempenho com investimento reduzido.Estratégia: Use modelos econômicos para maioria dos agentes, reservando premium apenas para funções críticas.
Workflows Especializados
Para expertise específica: Escolha modelos otimizados para seu principal caso de uso: Claude 4 em código, Gemini 2.5 Pro em pesquisa, Llama 405B em function calling.Estratégia: Selecione conforme a principal função da crew, garantindo alinhamento de capacidade e modelo.
Empresa & Privacidade
Para operações sensíveis: Avalie modelos open source como Llama 4 series, DeepSeek V3 ou Qwen3 para deployment privado, mantendo performance competitiva.Estratégia: Use open source em infraestrutura própria e aceite possíveis trade-offs por controle dos dados.
Tendências de Performance: O cenário atual mostra competição forte entre modelos de raciocínio (o3, Gemini 2.5 Pro) e equilibrados (Claude 4, GPT-4.1). Modelos como DeepSeek R1 entregam excelente custo/performance.
Trade-off Velocidade x Inteligência: Modelos como Llama 4 Scout priorizam velocidade (2.600 tokens/s) e inteligência razoável, enquanto outros como o3 maximizam raciocínio em detrimento de velocidade/preço.
Viabilidade Open Source: A distância entre open source e proprietários diminui a cada mês, com Llama 4 Maverick e DeepSeek V3 entregando performance competitiva a preços atrativos. Inferência rápida via Groq maximiza custo-benefício nesses casos.
Testes são essenciais: Rankings servem de orientação geral, mas seu caso
de uso, prompt e critério podem gerar resultados distintos. Sempre teste
modelos candidatos com suas tarefas e dados reais antes de decidir.
Inicie com opções consagradas como GPT-4.1, Claude 3.7 Sonnet ou Gemini 2.0 Flash, que oferecem bom desempenho e ampla validação.
2
Identifique Demandas Especializadas
Descubra se sua crew possui requisitos específicos (código, raciocínio,
velocidade) que justifiquem modelos como Claude 4 Sonnet para
desenvolvimento ou o3 para análise. Para aplicações críticas em
velocidade, considere Groq aliado à seleção do modelo.
3
Implemente Estratégia Multi-Modelo
Use modelos diferentes para agentes distintos conforme o papel. Modelos de
alta capacidade para managers e tarefas complexas, eficientes para rotinas.
4
Monitore e Otimize
Acompanhe métricas relevantes ao seu caso e esteja pronto para ajustar modelos conforme lançamentos ou mudanças de preços.